Introduction
Background and context
An Enterprise system is one capable of supporting a large organization; providing access to large, diverse collections of data, but in an integrated way; supporting a wide variety of applications in a secure and reliable manner; and serving large numbers of users in fast response real-time. Large corporations have, of course, operated computer systems in support of their core businesses for many years -- think database systems. What is different about an enterprise system is that multiple data sources and applications are integrated into a single overarching framework that is accessed largely through the Web.
The software used to build enterprise systems comes in two basic flavors: Microsoft's .Net and Java EE (Java Enterprise Edition). The .Net infrastructure, of course, come from a single vendor -- Microsoft -- whereas Java EE is an architecture, implementations of which are offered by a number of different vendors. IBM offers its WebSphere brand of products; formerly BEA, now Oracle offers WebLogic; Apache offers Geronimo; and JBOSS is an open source application server. In the remainder of this discussion, we will not discuss .Net software further and, instead, focus on Java EE systems, in general, and on IBM's implementation of that standard, in particular, in its WebSphere and Rational product lines.
Problems and Issues
A fundamental problem for enterprise systems is their inherent complexity and the subsequent difficulties people have in designing and building them. To understand why these systems are so complex and so hard to build, one must understand their inherent architecture and the nature of their implementations.
Java EE systems are highly layered. This results from a combination of the
particular
resources included in the Java EE specification and a set of best practices that
have evolved for their use. Java EE distributions include libraries for
creating view objects (e.g., JSPs), navigation control (e.g.,
Struts and Faces), transactions and access control (e.g., Session
EJBs), domain models (e.g., Java), and persistence (e.g., Entity
EJBs and JDBC). There is a chicken and egg relationship between resources
and layered designs -- because resources, often for historical or legacy
reasons, are divided into particular collections, designers tend to use them in
corresponding functional layers; because designers prefer layered designs, new
resources are often added as packages that support a particular functional layer.
A typical Java EE layered architecture is shown below.
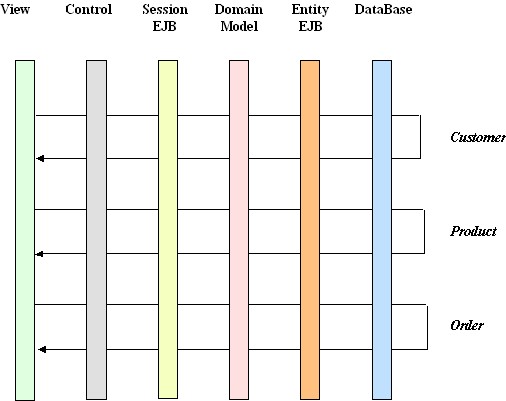
The different layers present very different programming models. That is, the tools for a given layer and the way a developer thinks about programming that layer are quite different from those for a different layer -- for example, programming a user interface control layer is nothing like programming a Session EJB or a domain model component. Comprehensive development environments, such as IBM's Rational Application Developer or WebLogic's Workshop Development Environment, ease the task, but these are large, complex, and expensive tools that produce voluminous output not easily understood by the programmer inexperienced in Java EE systems.
At the end of the day, although the Java EE architecture offers many advantages for building and maintaining large enterprise systems, there is danger that the architecture could sink under its own weight and complexity. What is badly needed is a way to build basic Java EE systems more quickly and easily, and to help programmers new to this architecture ascend the steepest part of the learning curve more quickly.
The goal of our research is to enable programmers to automatically generate most of the code and deployment descriptors for simple Java EE applications. These files are embedded within generated WebSphere Studio or Rational Application Developer project structures. Programmers can then perform a few simple "clean-up" steps and test the generated application. They can then study the generated projects, files, and descriptors to help them understand how they work. They can also alter them to experiment with the design and to see how such changes affect the generated solutions.
We expect that expert programmers using our resources will be able to develop simple prototype application that might normally take 4 to 8 hours in, at most, a half-hour. Novice Java EE programmers should be able to get over the worst of the learning curve in several weeks and then be able to create simple Java EE applications in a few hours. In a university undergraduate setting, this process currently takes 4 to 5 weeks; reducing it to 1 to 2 weeks would be a major advantage, allowing more time for design and project considerations vs. time required to learn technical details.
Specification and Design
To generate an application, the programmer must define two descriptions of the system, represented as XML files. One describes the application semantics. The other describes a particular layered implementation that can meet the application's performance and design requirements. We refer to these descriptions as the appl.xml and impl.xml files. Whereas the programmer may create either file by hand, we provide on-line tools, described below, that greatly simplify and speed-up the process.Approach
The application description includes the following components:Application Description
- user types
- data objects, including properties and methods
- interactions between user types and data objects
- relationships between data objects.
The first two of these are self-evident. The third -- interactions between user types and data objects -- constitutes method level access control for objects. That is, it describes which methods for a given object a particular user type may or may not execute. The last, relationships, conforms to the familiar dbms notion of relations. In an object-oriented system, relations are normally expressed as getter and setter methods on objects, such that one may use a get or set method on one object to access or assign a second object. We have followed this convention for implementing relationship-related methods in our generated code.
Example: application description.
The same application description could be used to generate different solutions involving different layers and/or resources. For example, an application that includes just a few pages filled with content obtained from a database could be implemented as PhP pages served from an HTTP container. However, an application that includes more complex and/or dynamic page navigation and one for which a more substantial object-oriented language is desired might be more appropriately implemented in Java, using JavaServer pages served from a Java Server or so-called Web Container. A still more complex application that requires transactions, asynchronous messaging, and, especially, scaling and load balancing, would be implemented more appropriately using Java EE resources and an EJB Container.Implementation Description
More specifically, our system supports five different layered options:
- a seven layer Java EE implementation that includes model, view, and control layers in the Web container; EJB Session, domain model, and Entity EJB layers in the EJB container; and a DBMS persistence layer;
- a five layer Java EE implementation intended for early testing that concludes with a domain model stub layer and no Entity EJB or DBMS layers;
- a four layer implementation that includes the three Web container layers and a DBMS persistence layered accessed through JDBC;
- a three layer implementation intended for early testing that includes the three Web container layers but concluding with a model stub layer and not DBMS layer;
- a two layer implementation intended for an HTTP container that includes a PhP view layer and a DBMS persistence layer.
The particular implementation that would appear to be be best suited for a given application is inferred by a project tool, described below, based on user input. The resulting implementation description includes the following components:
- containers (HTTP, WEB, and/or EJB)
- layers within container (view, control, model, etc.)
- within-container objects (e.g., Struts ActionForms)
- between-container objects (e.g., databeans)
- parameters (e.g., dbms access parameters)
Example: implementation description
To facilitate defining and editing the appl and impl descriptions, we have developed a tool we call ProjectManager. It is a Java EE application that runs within a WebSphere application server. Multiple users may register, login, and form access groups. Members of these groups may then invoke a Java Applet that includes panels for defining the following parts of an appl xml file:Tools
- user types
- data objects, included properties/variables and methods
- interactions between user types and data object methods
- relations between data objects
A screen image of the Applet overview panel is shown below:
An image of the data object tab is also shown:
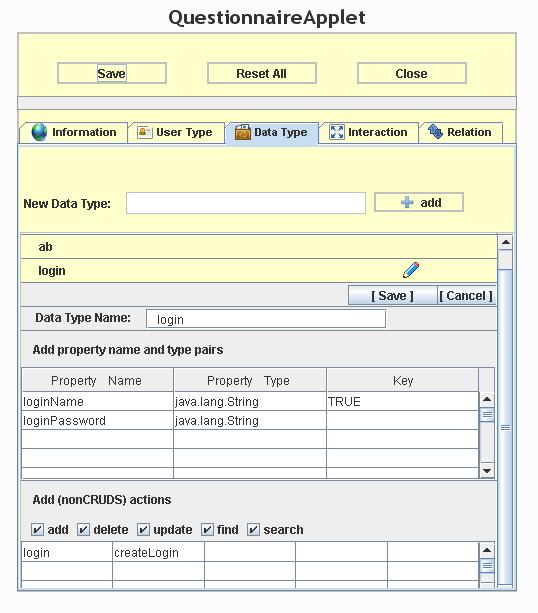
In this example, the application includes three data objects: user, login, and ab. The login data object includes two properties, loginName and loginPassword. In addition to the five CRUDS methods, it also includes createLogin and login methods.
To facilitate creating the implication description, we provide a checkbox questionnaire. Based on the answers to these non-independent questions, we try to infer the simplest simplest layered implementation that satisfies all of the constraints. A portion of the questionnaire is shown, below:
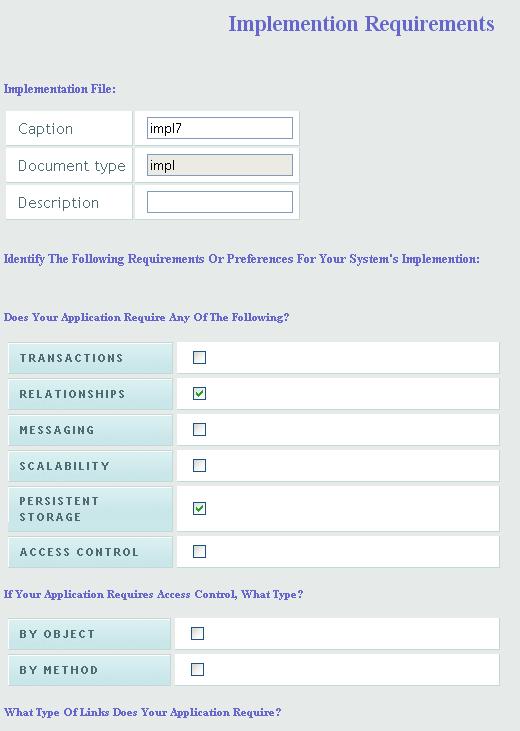
On the basis of a user's answers to these and some fifteen additional questions, we deduced that the most appropriate architecture for this application would be a seven-layer Java EE one intended for deployment in WebSphere.
Once defined or generated, the appl.xml and impl.xml files may be stored in the ProjectManager's database, after which they may be edited and/or downloaded via the Web to be saved in the user's file system and used with our application generating plugins.
Application Generation
Once a user has obtained appl.xml and impl.xml files -- for example, by developing them in the ProjectManager tool, downloading them, and saving them in the local file system -- he or she may automatically generate the application. Generation is done using a plugin within a comprehensive development environment. We have developed two such plugins -- one for WebSphere Studio 5.1.2 and another for Rational Application Developer 7.5. Because of WSAD's smaller footprint and proven reliability, we continue to maintain it, although future work is likely to be focused increasingly on the RAD version.Approach
The interface for the plugin is shown, below:
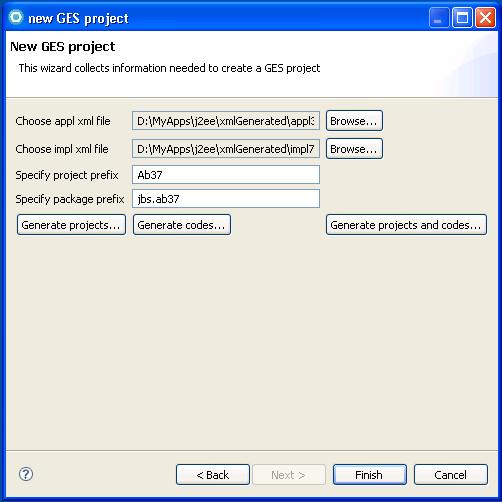
Invoked from within the J2EE perspective in either WSAD or RAD, the plugin asks for the locations of the appl.xml and impl.xml files. It also allows the user to specify a project name prefix, in this case Ab37, that will be appended to the generated names for all application projects within the development environment. A package prefix, in this case jbs.ab37, that will be appended to all generated Java package names can also be provided. For example, in the image shown below, one can see the Ab37Ejbentity project and in its ejbModule folder, the jbs.ab37.ejbentity.ab package.
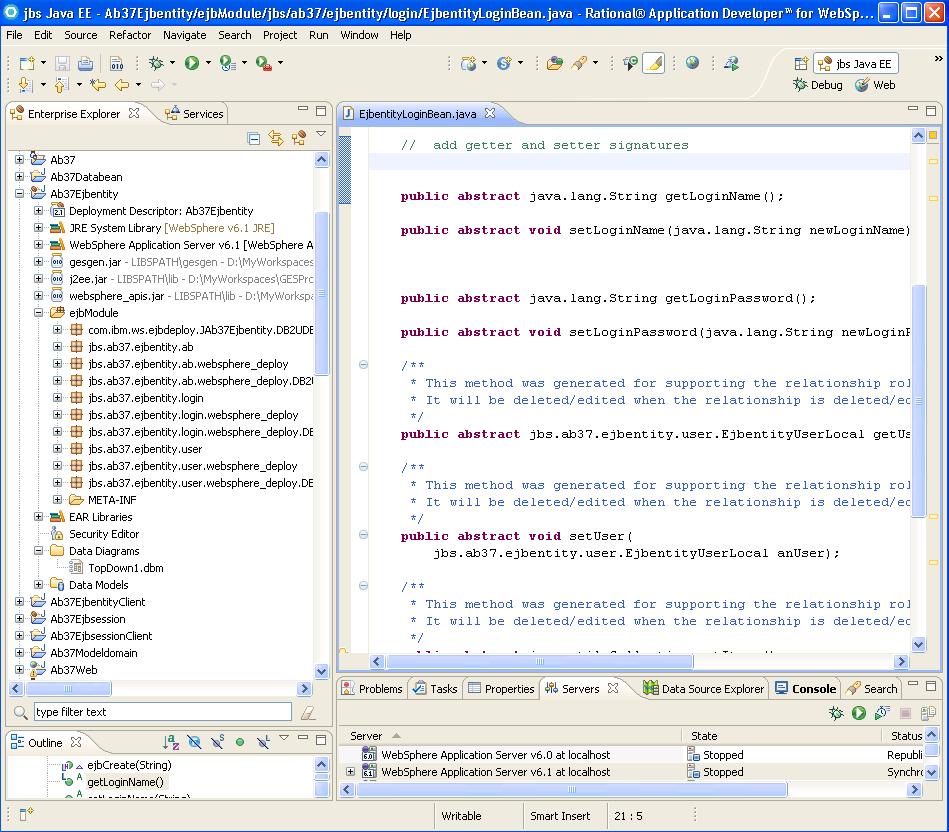
The plugin first generates the complete project structure, Java packages, and configuration files for the application. It then generates and stores within the project and package structures the Java code for the various layers of the application (or PhP code, for those applications that include only two layers within an HTTP container). Below is an example application generated within RAD 7.5:
Manual Steps
Approach
Once the application has been generated, within either the RAD or WSAD environments, the user must perform several cleanup steps in order to actually run it. These steps include invoking wizards within the RAD or WSAD environments so that they perform support functions, mapping and connecting the application to the database, implementing non-CRUDS methods, and updating Struts navigation mappings. We will discuss these various operations with respect to an EJB application in more detail, below. We also provide several tasklists that guide the user through them:
When one develops an application within either WSAD or RAD, a number of wizards are provided that not only generate code for the specific task but perform necessary side-effect tasks. For example, when one creates a reference in a Session EJB project, in addition to updating local deployment and configuration files, the wizard also registers the object with the JNDI server. Whereas we could conceivably provide that function in our plugin, we elected to omit it and rely on environment wizards for such support as a more cost-effective allocation of our time and resources. We describe some of these steps and the tradeoffs we made, following.Invoking Wizards
In an Entity EJB project, one is likely to have to perform three or four steps, depending on the nature of the application. If the application includes relationships, one should edit them in the deployment descriptor wizard by simply stepping through the various pages of the wizard but changing nothing. When the "edited" relationship is saved, the wizard generates the necessary getter and setter methods in the objects to support foreign key navigation. Similarly, editing an EJB query also causes the wizard to generate access methods with which to invoke the query in the home interface objects.
In a Session EJB project, one must ensure that any downstream object, such as a Domain Model, that requires access to an Entity EJB can locate that EJB. WebSphere provides such access through a JNDI reference. Creating and registering a reference is done through the Session's Deployment Descriptor. Although the GES plugin creates an initial version of those references, they should be redefined and saved in the Session wizard in order to register them with the JNDI server.
Map EJBs to DataBase
One of the advantages of using Java EE and EJBs over basic Java and JDBC is the support for database interaction provided through Container-Managed Persistence. This automatically-generated support allows the J2EE container, e.g., WebSphere, to handle database queries and updates without direct programmer-generated code. This is accomplished at a deployment level and through support code generated by a wizard. The key steps are generating a mapping between EJB data objects and dbms tables and then editing the mapping to refine column names, data types, data lengths, etc. Providing this step in WSAD is straight forward and accomplished through the mapping editor. With WSAD, one can invoke the table editor to refine the generated default mapping. For tables that include a dozen or more columns, doing so is important since the default length of some fields -- especially VARCHAR fields that default to 250 -- can aggregate to more than the default cache size for the dbms, causing failure when the mapping is exported to the database.
Unfortunately, there appears to be no way to invoke the table editor in RADS; we are continuing to try to identify a way to do so, but for now this appears to be a significant stumbling block for using RADS for applications that require EJB top-down mappings.
Implement Non-CRUDS Methods
The GES superclasses provide the five CRUDS methods: add (create) retrieve, update, delete, and search. They are supported by abstract methods that individualize them for specific data objects. The classes generated by the GES plugins implement those abstract methods. For non-CRUDS methods, the plugin generates method stubs that include the signature for the method but no implementation of any function internal to the method. Since there is no way for the plugin to know about such internal function, based on the information available in the application description, the programmer must manually code this. However, we have found that in many cases this code is quite simple and/or relies on the CRUDS methods available to it within the GES superclass the generated class extends.
Update Struts Configuration
The Web portion of the application includes view, control, and model layers. Currently, GES generates implementations for these layers based on the Struts 1.1 framework. A key component of a Struts implementation is the struts-config.xml file which defines abstract names for components, maps them to their implementation classes or path references, and specifies necessary parameters. Included in this configuration are navigation links between components. For example, which action or JSP should be invoked when a login action fails? or when it succeeds? Navigation links are defined by forward elements that are part of action tags. GES generates placeholder elements for both success and failure conditions. The programmer must edit these to define that actual navigation links that the application requires as well as add any additional links that go beyond basic success or failure conditions.
System Architecture
Approach
Overall project architecture is shown, below:
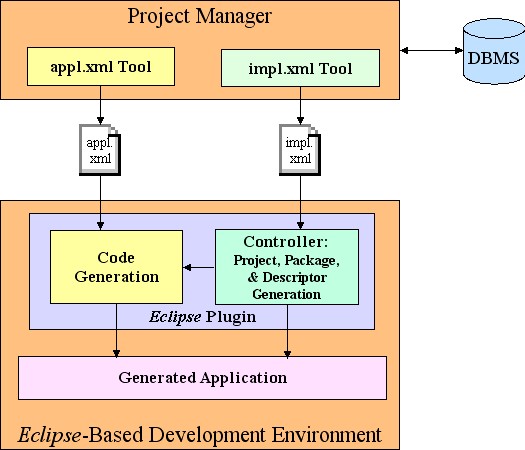
Figure 7: GES Project Architecture
It includes four types of components:
- Project Manager that generates application and implementation descriptions
- Plugins that generate the actual application within either a WSAD or RAD development environment
- Superclasses for the various layers of the generated application
- Templates that generate extensions of the superclasses and comprise the substantive part of the application.
Project Manager
The Project Manager is a Java EE application, deployed in a WebSphere 5.1 platform; it was described, above, with respect to Specification and Design. To summarize briefly here, it provides three main functions. First, as the name indicates, it enables users to manage project materials. It supports multiple users, identified by logins and passwords, groups of users, and it provides access control for their project resources. Second, it provides a tool that greatly simplifies the creation, editing, and storing of application descriptions. The tool, implemented as a Java Applet and shown in Figures 2 and 3, enables users to define User Types, Data Objects including their properties and methods, Interactions between User Types and Data Objects (which users can/cannot invoke which methods on which objects), and Relationships between Data Objects. Third, it includes a different tool to help users identify requirements that determine different layered implementations. This tool is implemented as a JSP questionnaire, a portion of which is shown in Figure 4, and consists of some 20 odd non-independent questions regarding system requirements as well as additional parameters needed for DBMS access, if persistence is required. We use an heuristic to analyze these responses to make a "best guess" at an appropriate implementation. If the user does not like our inferred implementation, he or she may edit the questionnaire and "nudge" it toward a more desirable one.
Eclipse Plugins
An Eclipse plugin, also written in Java, generates the implementation. We have two versions of the plugin: one for WebSphere Studio 5.1.2 and another for Rational Application Developer 7.5. They both function the same but have slightly different appearances because of the underlying version of Eclipse on which each environment is based. They take as input an application description and an implementation description, both XML files as described above. The user may also specify a project name prefix and a Java package prefix; they are appended to conventional names for the J2EE projects and the Java code generated by the plugin.
The plugin is built as a conventional Eclipse plugin using a wizard as a user interface. Once user data are input -- the two XML descriptions and the two prefixes -- generation is initiated as a long-running thread. That object, in turn, calls specialized generators to build the individual Java EE projects that comprise the application. Control for generation is provided by the implementation XML file. That is, the plugin first generates all of the projects necessary for each container included in the description. For each container, it generates the project(s) required to implement the layers contained within each container. Within each of these projects, it first generates packages for the Java code and then the code, itself. Finally, it generates configuration files, deployment descriptors, and other meta files.
The application XML description file provides parameters for generating the Java code for each data object, package names that include a reference to these objects, and tags within various meta files. For example, object names, their properties and methods. To make access to these parameters easier, the application description XML is parsed and its values transferred to a bean-like model with convenient getter and setter methods. Actual code generation for individual classes and other component types (e.g., JSPs and PhP files) is done using templates, simplified by a set of superclasses. These components are described next.
GES Superclasses
A key realization that underlies our work is that much of the function for many database-oriented applications can be provided by five basic methods: adding new items to the database, retrieving a known item, updating an existing item, deleting an item, and searching for (possibly) multiple items based on column values within a given table. These five methods are often referred to as CRUDS methods. Within a given Java EE layer -- for example, the Session EJB layer -- the implementations of the CRUDS methods for two different data objects -- for example, a user object and a product object -- can be virtually the same except for the name of the object and, perhaps, the name of the Domain Model that will be called.
Consequently, we have developed superclasses for all of the Java classes to be generated. These superclasses include abstract methods for all data object-specific parameters and implement the CRUDS methods in general ways, calling on the abstract methods for parameters where needed. Of course, the full Java code could be generated for individual objects within layers, but the superclasses greatly simplify the templates since they need only implement the abstract methods. Some superclasses require as many as ten or twelve abstract methods, but most require only three or four. Even so, most of these methods are relatively simple to generate.
Code Generation Templates
Code generated for the various data objects within the different layers is generated using Eclipse's Java Emitter Templates (JET), part of its Eclipse Modeling Framework (EMF). Whereas both WSAD and RAD include versions of JET, the Eclipse version is simpler and adequate for our purposes. Creating a JET template for a Java file (or other file type, including JSP and PhP ) is a two-step process. First, one writes a text file into which may be embedded Java logic that will be executed when the file is saved. This executable code is set off from the basic text of the file by special tags adopted from JSP. For example, scriptlets are marked by <% . . . %> tags, and conventional expression and declaration tags are also recognized by JET. This executable code is used to generate repeated blocks of text, perform conditional logic, and insert parameters from a model. The text file is marked by a .javajet suffix. Second, when a file is saved, the embedded Java code is executed and the resulting file -- with its repeated text, inserted parameter values, etc. -- is saved to a different location. This file comprises a template as used by the plugin to generate the application code. It is a basic Java file that relies on a bean-like model for parameters. When it is executed by the plugin, it generates the Java code that is inserted into the project and package structures for the application. Of course, if the text file in the first step was JSP, executing the Java template would produce a JSP file; similarly, for PhP.
Project Status and Future Work
The system described above is operational. Users may download and install the WSAD and/or RAD plugins in their systems. They may also login to the Project Manager system, create and save multiple application and implementation descriptions, and download them to their local machines. After that, they may start their development environments, invoke the plugin, and generate a project structure for their application. Once that is done, they must perform the manual steps, outlined above, to produce a running system. For a simple three or four object application, this should take some 10 to 15 minutes, perhaps a bit longer the first few times one does it. To add "niceties" such as welcome and logoff pages, to refine generated JSP pages, etc. will take additional time. But the process should be an order of magnitude faster than building the application from scratch.Work Completed
Work will continue on the current, operational components, particularly to reduce the number of manual steps required for cleanup. We also plan to have a half-dozen users work with the system in the near future and will evaluate and refine it in response to their experiences. However, our main focus will shift to the activities described next.
Once one has descriptions for several applications, a natural progression might be to combine them into a composite description in order to then generate a system that includes the features of the constituents. For example, consider the following scenario. A user develops the description for an application that supports an online addressbook. It wouldn't be a very practical application since all users would share the same data. But then suppose the user develops a second application that handles user registration and login. This second application could be implemented and run independently from the first. But suppose they could be combined: the composite application might then allow users to register and login, but each could then be provided with an entirely separate addressbook for his or her own personal data. Now, imagine a third application that, like the original addressbook application, supported a music catalog. If it could be combined with the user management and addressbook applications, users would also be able to manage both their music and their personal contacts in the same application. Etc. for other forms of data, such as photographs, recipes, calendars.Composing Applications
The underlying concept here is to think of building applications from a library of simple component descriptions. These descriptions would, of course, be extremely light weight. Tools included in the project manager would allow users to store these component descriptions and to compose them to build up descriptions of larger, more complex applications. Since each of these composites would, itself, be a legitimate application description, each could be down loaded and used to generate an implementation for that application or it could be used incrementally in another composition to build a still larger application. We have built a few simple compositional tools and are currently exploring their use and implications.
As one combines smaller applications to form larger ones, the process begins to feel a bit "mathematical." That is, combining two applications may seem like an "addition" operation. If one provides an inverse composition function, whereby one can remove a constituent from a combined application formed earlier, that process may seem like a "subtraction" operation. In both of these cases, we have defined composition functions that either simply add to the description of one application the data objects in the second or the reverse. But in some instances, if one combined the data objects, one might wish to not just include them as independent objects but to define a relationship, in the database sense, between them. Doing so might seem like a "multiplication" operation, whereas undoing such a composition might be thought of as a "division" operation.Algebra of Applications
Thus, we are finding that certain compositional operations have a seemingly natural correspondence to simple algebraic operations. This is leading us to ask the question:
Can we develop an algebra of applications that would describe, formally, a set of rules for building valid, more complex applications from simpler constituent applications and would let us reason about the results?
An area of math that includes the four basic arithmetic operators and seems relevant is Field Theory. Examples of fields include the rational numbers, real numbers, and complex numbers. We are currently trying to define an algebra of applications as a mathematical field.
A third area in which we are working is trying to apply our ideas to the notion of patterns. Design patterns have, of course, made a dramatic impact on software engineering. Is there a comparable notion of pattern that can be applied at the application level? Martin Fowler's work on Analysis Patterns makes us think this may be so. We are interested in exploring this possibility, but have not delved deeply into the idea yet.Application Patterns