So far, we have considered concurrency schemes for synchronizing accesses to shared databases - that is, shared objects supporting only read/write operations. Object transactions are concurrency schemes for synchronizing accessed to shared objects on which arbitrary operations can be supported. [ Schwarz Spector ]
How should concurrency schemes be adapted when accesses are made to shared objects? The answer depends on how much of the application semantics is available to the concurrency scheme. To understand the nature of such a concurrency scheme, let us introduce the notion of a dependency relation, D (X,Y), which is a relation formed between transactions based on the order in which they execute certain kinds of operations, defined by X and Y, on a shared object. A transaction Tj depends on transaction Ti with respect to a dependency relation D Tj <D Tj
if Ti performs an X operation before Tj performs a Y operation.
Consider first the situation when the concurrency scheme has no semantic information, that is, has no information regarding the effect of an operation on an object. In this situation, we must assume that an operation can perform arbitrary actions. Let us define one operation kind, any, and the dependency relation: D = D(any, any)
Then, a transaction schedule is serializable if this dependency relation does not introduce any cycles, that is, if transaction Ti performs an operation on an object before transaction Tj, then Tj does not perform an operation on the object before transaction Ti.
Also, assume that we wish to prevent cascaded aborts. Then we need to ensure that a transaction performs an operation on a shared object only if all transactions that have accessed the object have committed.
Now assume that we know which operations are reads and which are writes. We can define four dependency relations:
D1 = D(R, R) D2 = D(R, W) D3 = D(W, R) D4 = D(W, W)The dependency D1 is insignificant in that it cannot be observed. So to guarantee serializability of a schedule, we just have to ensure that it does not create cycles in the dependency relation D2 U D3 U D4, which is more liberal than D = D1 U D2 U D3 U D4. Thus, this scheme will allow the schedule of Figure 3 but not Figure 4.
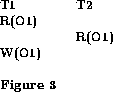
but not
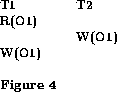
To ensure that there are no cascaded aborts, we have to ensure only that no D3 dependencies exist among overlapping transactions, which is again more liberal than ensuring no dependencies exist.
Finally, assume that we know type-specific semantics of the operations. In this case, it is possible that we can have an even more liberal scheme for ensuring serializability and no cascading aborts. Consider the example of a queue supporting the QEnter (q, e) (abbreviated as E(e)), and QDelete (q) (denoted below as D(e)), where e is the element deleted operations. We can define the following dependency relations:
D1 = D (E(e), E(e')) D2 = D (E(e), D(e')) D3 = D (E(e), D(e)) D4 = D (D(e), E(e')) D5 = D (D(e), D(e'))In this case, the dependencies D2 and D4 are insignificant. Thus, assuming that queue, Q, has elements A and B, schedule of Figure 5 is serializable:

If we were to model QEnter as a write and QDelete as a read followed by a write, then this schedule would not have been allowed. Since T1 <D2 T2 dependency is insignificant, this schedule is indeed serializable. Similarly, to prevent cascaded aborts, we have to ensure no D3 and D5 dependencies occur among interleaving transactions. The dependency D1 is insignificant since and is similar to the W,W dependency.
A locking-based scheme for supporting this scheme must support locks of the form LockClass(data) where LockClass corresponds to operation type and data corresponds to explicit or implicit operand of the operation. The compatibility matrix of Figure 6 describes a locking scheme for Queues:
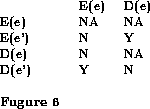
Here we assume, that QEnter must ask for a lock on the element to be added, which is held till the end of transaction. Similarly, QDelete must ask for a lock on the head of the queue, which is also held until end of transaction. This scheme allows a transaction entering items to interleave its steps with one removing items.
We may further refine our transaction model by defining a weaker notion of consistency than serializability. This constraint is too strong in some situations. Let us return to our example of queues. We may want to use the queue as simply a buffer between producer and consumer processes. FIFO queues used as buffers ensure that items are removed in the order in which they are entered. We may be satisfied with weakly-FIFO queues-- queues that allow items to be removed out of order but ensure there is no starvation. For such data structures, we can ignore the D1 and D5 conflicts, that is, we can allow transactions to overlap their entries and removals in a non-serial way. Thus, the only relationship we serialize is the D3 relationship. The locking scheme changes to Figure 7:
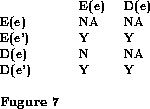
This scheme allows transactions entering and deleting items to interleave their steps but is not serializable.