My Papers & Projects
2014
Abstract:
Dataflow software architectures are prevalent in prototypes of advanced automotive systems, for both driver-assisted and autonomous driving. Safety constraints of these systems necessitate real-time performance guarantees. Automotive prototypes often ensure such constraints through over-provisioning and dedicated hardware; however, a commercially viable system must utilize as few low-cost multicore processors as possible to meet size, weight, and power constraints. In short, these platforms must do more with less. To this end, we develop cache-aware and overhead-cognizant scheduling techniques that lessen guaranteed response times without unnecessarily constraining platform utilization. We implement these techniques in PGMRT, a portable middleware framework for managing real-time dataflow applications on multicore platforms. The efficacy of our techniques is demonstrated through overhead-aware schedulability experiments and runtime observations. Results for our test platform show that cache-aware clustered scheduling out- performs naïve partitioned and global approaches in terms of schedulability and end-to-end response times of dataflows.
G. Elliott, N. Kim, J. Erickson, C. Liu, and J. Anderson, “Minimizing Response Times of Automotive Dataflows on Multicore.”, Proceedings of the 20th IEEE International Conference on Embedded and Real-Time Computing Systems and Applications (RTCSA), August 2014. (to appear)
Copy of paper available here, with appendix.
Github project for PGMRT here.
LITMUSRT Linux kernel patches here.
Minimizing Response Times of Automotive Dataflows on Multicore
4/3/14
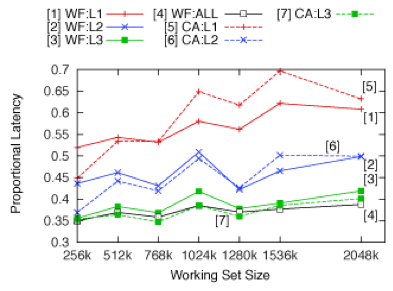
This figure plots observed end-to-end response times at the 99th percentile (near worst-case behavior), normalized by graph depth times period, for graphs with increasingly heavy data working set sizes. The “WF” lines depict observations for “worst-fit” assignment of graph nodes to CPU clusters, which evenly distributes work across clusters. “CA” lines depict observations for “cache-aware” cluster assignment, where related nodes are assigned to the same, or adjacent, clusters in an effort to promote cache reuse. Response times are shorter (better) under CA, provided that the cache is not overly utilized. WF performs better under heavy cache use since there is increased cache contention, and it become more important to distribute work among clusters.