Background and context
Since the World Wide Web appeared in 1990 and went public in 1993, it has evolved from an application that allowed physicists in Europe and the US to exchange documents to the social and technical force that it is today. Indeed, it is not just a huge repository of information or even the dominant application on the Internet used by billons of people. It has become the interface to an ever expanding collection of applications and services that range from ecommerce to social networking to business processes, both retail and back-end. Many corporations, organizations, and government entities do their business through systems that are accessed through the Web. To meet these needs, a new type of system has appeared, referred to as an enterprise system.
An enterprise system is generally thought of as a system that is capable of supporting a large organization; providing access to large, diverse collections of data, but in an integrated way; supporting a wide variety of applications in a secure and reliable manner; and serving large numbers of users in fast response real-time. Large corporations have, of course, operated computer systems in support of their core businesses for many years -- think of the role of database systems in the insurance industry or government services. What is different about an enterprise system is that multiple data sources and applications are integrated into a single overarching framework and that access is largely provided to users -- both public and private -- through a single interface technology -- the Web.
To support the load, enterprise systems often require many different computers which may be located in widely scattered locations, joined by the Internet. These highly distributed systems pose a number of challenges, both in their requirements and in their administration. For example, many such systems must include multiple machines that offer the same application or function to provide sufficient processing power to meet user demand. When a piece of software is updated or added, all of those similar machines must be updated. Some business processes involve distributed transactions that require operations located on different machines to all execute properly or all of the processes must be rolled back. Others involve multiple user interactions within a session context but a context which must extend over multiple computers. To support functions such as these, a new type of enterprise infrastructure software has emerged which is somewhat misleadingly referred to as distributed application server software.
This software comes in two flavors: Microsoft's .Net and J2EE (Java 2 Enterprise Edition). The .Net infrastructure, of course, come from a single vendor -- Microsoft -- whereas J2EE is an architecture and there are several sources for this type of software. IBM offers its WebSphere brand of products; formerly BEA, now Oracle offers WebLogic; Apache offers Geronimo; and JBOSS is an open source application server. There are several other J2EE application servers, but these currently dominate the market. In the remainder of this discussion, we will not discuss .Net software further and, instead, focus on J2EE systems. Our research has also relied on IBM's implementation of that standard, although our research should be extensible to other J2EE products.
Problems and Issues
A fundamental problem for enterprise systems is their inherent complexity and the subsequent difficulties people have in designing and developing them. To understand why these systems are so complex and so hard to build, one must understand their inherent architecture and the nature of their implementations.
J2EE systems are highly layered. This results from a combination of the
particular
resources included in the J2EE specification and a set of best practices that
have evolved for their use. J2EE distributions include libraries for
creating view objects (e.g., JSPs), navigation control (e.g.,
Struts and Faces), transactions and access control (e.g., Session
EJBs), domain models (e.g., Java), and persistence (e.g., Entity
EJBs and JDBC). There is a chicken and egg relationship between resources
and layered designs -- because resources, often for historical or legacy
reasons, are divided into particular collections, designers tend to use them in
corresponding functional layers; because designers prefer layered designs, new
resources are often added as packages that support a particular functional layer.
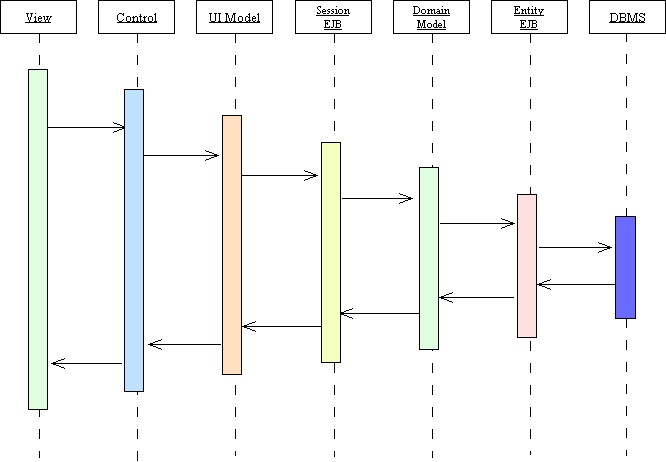
A view of a typical J2EE set of layers is shown in the figure that follows.
The resources that support the various J2EE layers were often developed independent of one another and/or came from earlier independent legacy systems. As a result, the different layers present very different programming models. That is, the tools a developer has at his or her disposal for a given layer and the way that developer thinks about programming that layer are quite different from those for a different layer -- e.g., programming a user interface control layer is nothing like programming a Session EJB or a domain model. Comprehensive development environments, such as IBM's WebSphere Studio and its more recent Rational Application Developer or WebLogic's Workshop Development Environment, ease the task, but these are large, complex, and often expensive tools. They also produce voluminous code, such that a simple J2EE application may contain several hundred separate program and deployment files. Some of them they will have to write, but many of them will be generated by the development environment. However, the programmer must understand all of them to the extent of knowing how they are related to one another and the particular tools that can be used to work with them.
At the end of the day, although the J2EE architecture offers many advantages for building and maintaining large enterprise systems, there is danger that the architecture could sink under its own weight and complexity. What is badly needed is a way to build basic J2EE systems more quickly and more easily, and to help programmers new to this architecture ascend more quickly the steepest part of the learning curve.
The goal of our research is to enable programmers to automatically generate most of the code and deployment descriptors for simple J2EE applications. These files will be embedded within generated WebSphere or Rational Studio project structures. The user can then perform a few simple "clean-up" steps and test the generated application. The application is generated from two XML files that describe the application and the particular layered design needed to meet its requirements. Both of these files are produced by tools developed as part of our project. We believe that using our resources expert programmers will be able to develop simple prototype implementations that might normally take 4 to 8 hours in, at most, a half-hour. Novices to J2EE programming will be able to study the generated projects, files, and descriptors to help them understand how they work and to alter the application design to see how such changes affect the generated solutions. In a university undergraduate setting, this process takes some 4 to 5 weeks; we hope to reduce this time to 1 to 2 weeks.
Approach
Application description
Implementation description
Tools
Approach
Plugin architecture
Approach
Generation of projects
Generation of package and folder structures
Generation of configuration files
Generation of support files
Approach
Superclasses and subclasses
Templates
Actual code generation
Code deployment
Overview
Deployment and housekeeping
Subclass method implementation
Work completed
Algebra for application descriptions
Application patterns
Combing patterns