OIDs will be 64 bits long. They will be treated as 16 hex characters, divided into four blocks of varying length.
The lowest order group ( 16 bits) will designate a particular graph object, such as the nodes within a graph and content objects. Normally, a graph will receive a seed which will serve as its own OID. It will then generate subsequent OIDs for its nodes from that seed. One implementation for this is that the graph OID has all of its low order bits set to zero and the OIDs derived from it are simply integers set to last_value+1.
The second group of values (20 bits) will designate a clustering object: the graph itself or a set of file content objects that are related, such as the content files for the nodes in a particular graph. This clustering concept will be invisible to the user and, hence, not part of the data model.
The third block (16 bits) will designate a partition of files, such as a set associated with a particular user or group.
The highest block (12 bits) will designate a high order resource at the IP level. It could represent different IP synonyms for the same DSN value, different machines, etc.
OIDs will be stored internally as 64bit integers, but they will be presented to the user as 16 hex characters divided into four block. Blocks will be colon delimited. Thus, [012:3456:789AB:CDEF] will be interpreted as:
Thus, a given GraphDomain may include up to 4k machines, each of which supports up to 64k partitions or users, each of which may have 2m graphs ro groups of files, each of which can include 64k nodes or individual files.
In memory tables and/or hashing are anticipated for the two high order blocks. The file system will access the third block. The mapping from object to location can thus be determined by masking low-order bits, (at worst)accessing two in-memory tables, and fetching a single file.
A workable implementation to solve this problem appears to be to not delete the node from the original graph but, rather, to mark it as invalid and store a pointer (URL) to the newly created node in a different graph. Additional function can be provided by also storing a pointer (URL) in the new node back to the original node and, hence, its original context. If the node is moved again, the linking would be extended, forming a doubly-linked list.
There are two costs for this strategy. First, the links must be maintained. Done is a simple way, this could be handled straight-forwardly on the client side when the node is "moved." If shortcuts are introduced, the implementation becomes more complicated. Second, when a hyperlink is followed, a process would have to verify that the node to which the hyperlink was connected is still valid; if not, it would intervene and fetch the pointed-to graph, etc., until a graph with a valid pointed to link is found.
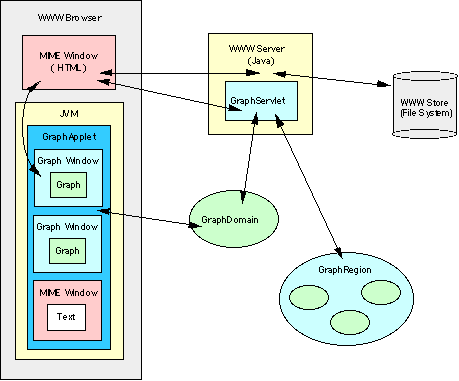
All public access to GraphContent objects will be through a Node for which a particular GraphContent object is designated as that Node's contents. Designation of the Node's contents will be through the GraphContent object's OID.
All copies of Nodes will be copy by value, including the Node's content reference. This results in a copy by reference for the content object. Thus, multiple Nodes can have the same contents while allowing each node to be a unique object.
As part of its responsibility to maintain Graph objects, the GraphDomain will most likely have to maintain a count of GraphObject references. When a Node is deleted, the GraphDomain must be notified. It would probably delete the Content object when the last Node is deleted that refers to it, but other semantics are possible.
HyperLinking is simplified by making all Nodes unique and, thereby, eliminating the need to determine the particular context in which a Node appears (since it can, by definition, appear in only one context). Further, since all objects in a Domain are referenced by OID, embedded hyperlinks -- consisting of an IP address for a particular GraphDomain and an OID -- are guaranteed so long as the node on the end exists within the Domain. Thus, hyperlinks will "follow" Nodes under moves to whatever contexts (Graphs) in which they appear.
This will also be true with respect to a Region, since we take the position that Regions support the same semantics as Domains. But it may require the forwarding of requests from one Domain to another and, possibly, for OIDs to be unique within Regions, not just Domains.
Several options are possible for deletions. Domains could simply report an error; they could return a message stating when the Node was deleted; or they might retain the Node -- disembodied from an Graph context -- for some period of time to provide recovery and meaningful response to user (when deleted, by whom, option to recover, etc.).
An open set of issues exists with respect to notification. What users/processes should be notified of what changes that occur in a GraphRegion?
Thus, HyperGraphs will be assigned OIDs similar to StructuralGraph OIDs. HyperNodes will have their own unique OIDs, also. Their content objects, however, will be OIDs for StructuralNodes. Hyperlinks will be pairs HyperNodes.
MoveNode . Moving a node from one StructuralGraph to another results in a new node object in the second context, with its own OID. The content object of the node is copied. The node in the first graph is not truly deleted, but marked as invalid. A forward pointer to the new node will be stored in the first node, and a back pointer will be stored in the new node to the first node.
DeleteNode. as in MoveNode, the node is not truly deleted, but marked invalid. Thus, an as-yet-to-be-defined restore operation could be supported.
CopyNode. Copying a node from one graph to another results in a new object in the second graph, with its own OID. The content object URL for the first node is copied to the second.
The key issue is the "multiline subway station" problem. Think of StructuralGraphs as providing one "line" of access, in which a user may move from one context to another by opening node contents or by ascending to a parent node for a graph. Think of HyperGraphs as providing a second "line" of access, in which a user may follow links form one HyperNode to another (and, subsequently, opening a given HyperNode's corresponding StructuralNode/Graph). If users are traversing the first line, enter a given StructuralGraph, how can they know what HyperGraphs are present for a given StructuralNode in that context?
The solution taken in DGS was to store within a given StructuralNode all of the HyperLinks that included it as an endpoint; however, that approach will not scale. What is needed is a scaleable design that will provide fast access for most needs and slower access for infrequent requirements.
Consider a typing of HyperGraphs. The author's HyperGraph should receive highest priority. Often, these Hyperlinks will exist as embedded anchors/URLs in HTML content objects, but not always. For Graph content objects, external HyperGraphs will be needed. The specific user's own HyperGraphs should receive second priority. This will require a Personal Identifier (PID) analogous to an OID. Third priority is group HyperGraphs in which the specific user is a member. A fourth and (much) lower priority is the HyperGraphs of other users for which the specific user has read access.
One way to address these needs is to introduce a search capability into the GraphDomain in which a mapping between StructuralGraphs (or StructuralNodes) and HyperGraphs is maintained. This is the problem that was avoided in the hierarchical structure of OID bits, but we don't currently have an alternative approach.