COMP 530: Lab 3: Synchronization
Due 11:59 PM, Saturday, Dec 3, 2017
Introduction
In this lab you will develop a multi-threaded simulation of the Internet's
Domain Name System (DNS),
which maps host names onto human readable addresses.
We are not going to build a true DNS server, but, for simplicity, are instead writing a
simulator of the typical requests a DNS server would see (and one that is
unique to our system).
The course staff have provided you with a simple, sequential implementation (with one small piece to add).
The sequential implementation will need synchronization to work properly with
multiple threads.
Your job will be to create several parallel verions of the code, with increasing sophistication.
As before, this assignment does not involve writing that many lines of code (you will
probably copy/paste the base code several times). The changes
you make will probably be in the tens of lines.
The hard part is figuring out the few lines of delicate code to write,
and being sure your synchronization code is correct.
We strongly recommend starting early and writing many test cases.
DNS Background
DNS maps human-readable host names onto IP addresses. For instance,
it maps the name www.cs.unc.edu to the IP address 152.2.131.244.
Each computer on the internet is configured to use one or more DNS servers
for name resolution. On a Linux system, the server used often stored in /etc/resolv.conf.
Note that the servers are listed by IP address, otherwise the system
would have an infinite recursion!
By convention, DNS servers typically run on port 53.
In resolving hostnames, resolution is actually done backwards.
For example, in resolving www.cs.unc.edu,
a server will start by figuring out which server is responsible for
the .edu domain, then query this server to find out the authoritative
DNS server for unc.edu, then query that server to find the authoritative
DNS server for cs.unc.edu, which then responds with the address
of the server named www.
In general, servers cache previously resolved addresses, so that a subsequent request
for the same host name can be serviced more quickly.
If you are curious to learn more about DNS, the Wikipedia article on DNS is a good place to start.
Tries
In our DNS simulation, we will use a trie to store the mappings of host names
to IP addresses. A trie is a space-optimized search tree. The key difference between
a trie and a typically search tree is that part of the search key is encoded
by the position in the tree.
Consider the illustration to the right:
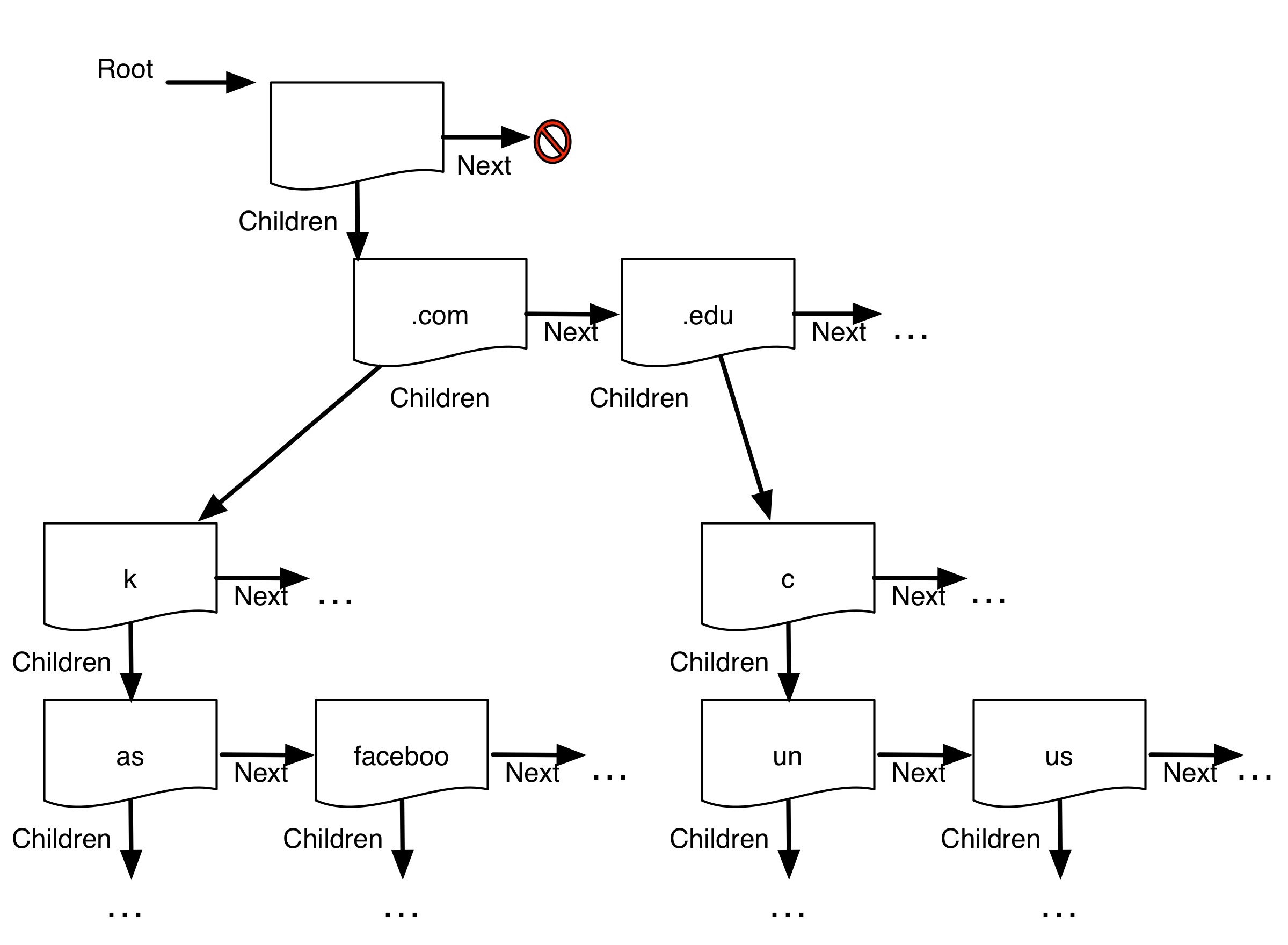 The root simply contains a list of top-level domains (.com, .edu, ...).
Each node has a list of children. This is a simple example, so under .com,
there is only a 'k' character, which then has children 'as' and 'faceboo',
which encode 'ask.com' and 'facebook.com'. Similarly, the '.edu' sub-tree
encodes 'unc.edu' and 'usc.edu'.
The root simply contains a list of top-level domains (.com, .edu, ...).
Each node has a list of children. This is a simple example, so under .com,
there is only a 'k' character, which then has children 'as' and 'faceboo',
which encode 'ask.com' and 'facebook.com'. Similarly, the '.edu' sub-tree
encodes 'unc.edu' and 'usc.edu'.
The key space-saving property of a trie is that common substrings
can be coalesced into a single interior node.
Technically, we are building a "reverse" trie, since most
tries that store a string would compare from left-to-right, not
right-to-left, as we are doing.
Finally, note that a DNS server doesn't necessarily have to use a trie,
many DNS servers use Red-black trees or other trees for various reasons.
We have provide you with some initial source code to start from,
here.
We have provided you with a simple interface in trie.h
and a sequential implementation in sequential-trie.c.
Do not use this implementation with more than one thread---it will
break because it does not use any synchronization!
As before, if you are curious to learn more about tries,
the Wikipedia article on tries is a good place to start.
Thread Programming Guidelines
Before you begin the assignment, (re-)read Coding Standards for
Programming with Threads. You are required to follow these
standards for this project. Because it is impossible to determine the
correctness of a multithreaded programming via testing, grading on
this project will primarily be based on reading your code not by
running tests. Your code must be clear and concise. If your code is
not easy to understand, then your grade will be poor, even if the
program seems to work. In the real world, unclear multi-threaded code
is extremely dangerous -- even if it "works" when you write it, how
will the programmer who comes after you debug it, maintain it, or add
new features? Feel free to sit down with the TA or instructor during
office hours for code inspections before you turn in your project.
Programming multithreaded programs requires extra care and more
discipline than programming conventional programs. The reason is that
debugging multithreaded programs remains an art rather than a science,
despite more than 30 years of research. Generally, avoiding errors is
likely to be more effective than debugging them. Over the years a
culture has developed with the following guidelines in programming
with threads. Adhering to these guidelines will ease the process of
producing correct programs:
- All threads share heap data. This requires you to use proper synchronization primitives whenever two threads modify or read the shared data. Sometimes, it is obvious how to do so:
char a[1000]
void Modify(int m, int n)
{
a[m + n] = a[m] + a[n]; // ignore bound checks
}
If two thread will be executing this function, there is no guarantee that both will perceive consistent values of the members of the array a. Therefore, such a statment has to be protected by a mutex that ensures the proper execution as follows:
char a[1000]
void Modify(int m, int n)
{
Lock(p);
a[m + n] = a[m] + a[n]; // ignore bound checks
Unlock(p);
}
where p is a synchronization variable.
- Beware of the hidden data structures! While your own variables on
the heap must be protected, it is also necessary to ensure that data
structures belonging to the libraries and runtime system also be
protected. These data structures are allocated on the heap, but you do
not see them. Access to library functions can create situations where
two threads may corrupt the data structures because proper
synchronization is lacking. For example, two threads calling the
memory allocator simultaneously through the malloc() library call
might create problems if the data structures of malloc() are not
designed for concurrent access. In that case, data structures used to
track the free space might be corrupted. The solution is to use a
thread-safe version of libc.
Linking with the -pthread
flag (included in your Makefile) is sufficient for libc using gcc.
Other compilers may require the -D_POSIX_PTHREAD_SEMANTICS
flag to select thread-safe versions.
Finally, not all libraries support thread-safe functions. If you include
extra libraries in your code, it is up to you to figure out whether they are thread safe,
or if calls must be protected by a lock.
- Simplicity of the code is also an important factor in ensuring
correct operation. Complex pointer manipulations may lead to
errors and a runaway pointer may start corrupt the stacks of various
threads, and therefore manifesting its presence through a set of
incomprehensible bugs. Contrived logic, and multiple recursions may
cause the stacks to overflow. Modern computer languages such as Java
eliminate pointers altogether, and perform the memory allocation and
deallocation by automatic memory management and garbage collection
techniques. They simplify the process of writing programs in general,
and multithreaded programs in particular. Still, without understanding
of all the pitfalls that come with programming multithreaded
applications, even the most sophistica ted programmer using the most
sophisticated language may fall prey to some truly strange bugs.
Getting started with the code
We have provided you with a sequential (single-threaded only)
implementation of a reverse trie, and a testing framework.
Take a few minutes to read and understand the source files:
main.c |
Testing framework, options and start-up code. You shouldn't need to modify this file. |
trie.h |
Function definitions for your trie(s). |
sequential-trie.c |
A single-threaded trie implementation. You may copy from this file as a starting point in the exercies below, or write your own trie. |
Note that typing make generates four different executables.
Currently, only dns-sequential will work, and only with one thread.
It will probably warn you that it is not dropping nodes yet.
You will create concurrent variations of the trie, which all share the code in main.c,
and interface definition in trie.h.
First, we will start by filling in one missing function in the sequential trie, just to get your
hands dirty with the code.
Hint: you can enable a lot of debug printing by uncommenting DEBUG=1 in main.c. Note that this is not a good idea beyond initial testing
because printf includes synchronization, which can inadvertently hide bugs.
That said, this style of macro-enabled debug messages can help you understand
what is happening, and easily compile out the messages once you believe
the code is working.
(10 points)
Complete drop_one_node() and check_max_nodes() in sequential-trie.c.
This function checks whether the tree has more than a configurable threshold of nodes,
100 by default. If the tree has grown too big, nodes should be dropped until the count
goes back to 100 or less. For this exercise, you can use any policy you like to
determine which nodes to drop. You will also need to make check_max_nodes
actually call drop_one_node.
A real, master DNS server would not simply drop entries like this. A caching server
might, though.
Be sure to test your code. We recommend adding a helper routine that asserts that
the number of reachable nodes in the trie equals the expected count.
(5 points)
Implement least-recently-used policy for when the trie gets too big.
Once you have the sequential version of the code working, you are ready to start implementing multi-threaded
versions of the code.
(15 points)
Implement a thread-safe trie in mutex-trie.c, using coarse-grained locking.
In other words, for this exercise, it is sufficient to have one lock for the entire trie.
To complete this exercise, we recommend using pthread mutex functions,
including pthread_mutex_init, pthread_mutex_lock,
and pthread_mutex_unlock.
Be sure to test your code by running with dns-mutex -c XXX
(where XXX is an integer greater than 1), in order to check that the code works properly.
Because multi-threaded code interleaves memory operations non-deterministically, it may work
once and fail a second time---so test very thoroughly and add a lot of assertions to your code.
Testing on a multi-core machine
Classroom is a 16 core machine. Be sure to test your code regularly on classroom,
as some bugs may only manifest with multiple CPUs.
The Delete Thread
In exercise 1, we had you implement support for shrinking the trie if it gets too big.
We want to now add a thread that monitors the trie and starts evicting nodes
if the tree grows too large.
We provided boilerplate code that creates a thread to run the delete code.
You can run the delete thread with ./dns-mutex -t.
This will create a thread that executes in the function delete_thread(),
which basically just calls check_max_nodes until the finished
flag is set.
Although you could simply have a thread run in an infinite while
loop, we can do better. In particular, we would like you to use condition variables
(e.g., pthread_cond_wait() and pthread_cond_signal),
as well as the existing mutex synchronization, to allow the delete thread to sleep
until there is work to do, and then to wake up once there is.
You will need to ensure that the subsequent trie implementations also support this behavior correctly.
It is not necessary for this to work with sequential-trie.c.
(30 points)
Add delete thread support to the mutex trie, using a condition variable
to allow the delete thread to wait until it needs work.
You need to also write at least two additional unit tests (e.g., under self_tests() or another test function),
that ensure that the node count is being properly maintained. Be sure not to break sequential trie,
and be sure this continues to work as you complete the next exercises.
Finer-Grained Locking
One way to improve concurrency is to allow multiple readers to execute concurrently, or a single writer.
For this exercise, you will add reader/writer locking to the code.
(15 points)
Implement a trie which allows concurrent readers, but mutually excludes writers
in rw-trie.c, using coarse-grained locking.
In other words, for this exercise, it is still sufficient to have one lock for the entire trie.
To complete this exercise, we recommend using pthread mutex functions,
including pthread_rwlock_init, pthread_rwlock_rdlock, etc.
Be sure to test your code by running with dns-rw -c XXX
(where XXX is an integer greater than 1), in order to check that the code works properly.
Because multi-threaded code interleaves memory operations non-deterministically, it may work
once and fail a second time---so test very thoroughly and add a lot of assertions to your code.
Finally, you can improve concurrency by supporting a single lock per node, allowing
threads to execute concurrently in different parts of the trie.
(40 points)
Implement a trie that uses fine-grained locking in fine-trie.c.
In other words, every node in the trie should have its own lock (a mutex is fine).
What makes fine-grained locking tricky is ensuring that you cannot deadlock while acquiring locks, and that a thread doesn't hold unnecessary locks. Be sure to document your locking protocol in your README.
Be sure to include support for the delete thread in this trie as well (extend exercise 3 to the fine-grained trie).
(up to 5 points, depending on solution quality)
The provided print function is a bit terse, and the user has to work to decode
the tree structure. Create a print function that clearly shows the levels of the tree
and better conveys the visual intuition of how the tree is organized.
(up to 10 points, depending on how elegant and correct your solution is)
Each level of the trie is organized as a singly-linked list, sorted by key.
Within a level, we could search faster using a skiplist. Read this article (or search the web)
to learn more about skip lists.
To complete this challenge, implement a skiplist to replace the current next pointer in each trie node.
Be careful to use the thread-safe pseudo-random number generator.
(up to 40 points, depending on how elegant and correct your solution is)
Important. This challenge is extremely hard, so do not start this before your lab is otherwise complete.
Getting all 40 points will require substantial documentation demonstrating the correctness of your implementation.
Read-copy update is an alternative to reader/writer locking
that can be more efficient for read-mostly data structures.
The key idea is that readers follow a carefully designed path through the data structure without holding any locks,
and writers are careful about how they update the data structure. Writers still use a lock to mutually exclude each other.
Read enough from the link above, or other sources, to learn how RCU works.
Task: Create a trie variant (rcu-trie.c) which uses RCU instead of a reader-writer lock. You may use
a 3rd party RCU implementation for the helper functions (e.g., rcu_read_lock, or write your own. You should write the rcu-trie yourself.
We highly recommend keeping this in a separate source file from your main assignment.
Note: RCU requires memory barriers in some cases, even for readers, so be sure you understand where these need to be placed.
Hand-In Procedure
For
all programming
assignments you will "turn in" your program for grading by placing it in a special
directory on a Department of Computer Science Linux machine and sending mail to the
TA alias
(comp530ta-f16 at cs dot unc dot edu). To ensure that we
can grade your assignments in an efficient and timely fashion,
please follow the following guidelines
precisely. Failure to do so will potentially result in your assignment receiving a
failing score for this assignment.
As before, create a directory named
lab3
(inside your
~/comp530/submissions directory). Note that Linux file names are case sensitive and
hence case matters!
When you have completed your assignment you should put your program and any other necessary
parts (header files, etc.) in the specified subdirectory and send mail to the
TA (comp530ta-f16 at cs dot unc dot edu),
indicating that the program is ready for grading.
Be sure to include "COMP 530" in the subject line.
In this email, indicate if you worked alone or with a partner (and both team members' names and CS login names, as many of you have emails different from your CS login);
be sure to cc your partner on this email.
If you used any late hours, please also indicate both how many late hours you used
on this assignment, and in total, so that we can agree.
After you send this email, do not change any of your files for this assignment
after sending this mail (unless you are re-turning in late, as prescribed by the lateness policy).!
If the timestamps on the files change you wi
ll be penalized for turning in a
late assignment. If your program has a timestamp after the due date it will be considered
late. If you wish to keep fiddling with your program after you submit it, you should make a copy of
your program and work
on the copy and should not modify the original.
All programs will be tested on
classroom.cs.unc.edu. All programs, unless otherwise specified,
should be written to execute in the current working directory. Your correctness grade will be based
solely on your program's performance on
classroom.cs.unc.edu. Make sure your programs work on
classroom!
Functional correctness will be based on your implementation's ability to
handle a wide range of allocation and free patterns,
not leaking memory,
as well as how thorough your test cases are.
Your code should compile without any errors using the provided Makefile.
The boilerplate code does include some warnings for unused variables;
these are hints and should be used by the time you are done.
The program should be neatly formatted (i.e., easy to read) and well-documented. In general, 75% of
your grade for a program will be for correctness, 25% for "programming style" (appropriate use of
language features [constants, loops, conditionals, etc.], including variable/procedure/class names),
and documentation (descriptions of functions, general comments [problem description, solution
approach], use of invariants, pre-and post conditions where appropriate).
Make sure you put your name(s) in a header comment in every file you submit. Make sure you also put
an Honor pledge in every file you submit.
This completes the lab.
Acknowledgements
Portions of the thread programming guidelines are adopted undergraduate OS course guidelines
created by Mike Dahlin and Lorenzo Alvisi.
Last updated: 2025-05-13 10:21:34 -0500
[validate xhtml]