Is the Optimism in Optimistic Concurrency Warranted? |
Donald E. Porter, Owen S. Hofmann, and Emmett Witchel |
Department of Computer Sciences, The University of Texas at Austin, Austin, TX 78712 |
{porterde, osh, witchel}@cs.utexas.edu |
Abstract:
Optimistic synchronization allows concurrent execution of critical sections while performing dynamic conflict detection and recovery. Optimistic synchronization will increase performance only if critical regions are data independent—concurrent critical sections access disjoint data most of the time. Optimistic synchronization primitives, such as transactional memory, will improve the performance of complex systems like an operating system kernel only if the kernel's critical regions have reasonably high rates of data independence.
This paper introduces a novel method and a tool called syncchar for exploring the potential benefit of optimistic synchronization by measuring data independence of potentially concurrent critical sections. Experimental data indicate that the Linux kernel has enough data independent critical sections to benefit from optimistic concurrency on smaller multiprocessors. Achieving further scalability will require data structure reorganization to increase data independence.
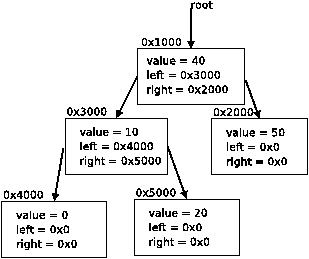
Critical Section 1 Critical Section 2 Critical Section 3 begin critical section; begin critical section; begin critical section; node = root→right; node = root→left; node = root; node→left = root→left→right; node→left = root→left→right; node→right = node→left; end critical section; end critical section; end critical section; r w r w r w 0x1000 0x2064 0x3032 0x1000 0x2064 0x2032 0x1000 0x1032* 0x1032* 0x3000 0x1032* 0x3000 0x1064 0x1064 0x3064 0x1064 0x3064 0x2000 0x2000
Table 1: Three critical sections that could execute on the tree in Figure 1 and their address sets. The read entries marked with an asterisk (*) are conflicting with the write in Critical Section 3.
make -j 30
to compile 27 source files from the libFLAC 1.1.2 source tree in
parallel.dcache_lock, a global, coarse-grained
lock. The dcache_lock protects the data structures associated
with the cache of directory entries for the virtual filesystem.
Directory entries represent all types of files, enabling quick
resolution of path names. This lock is held during a wide range of
filesystem operations that often access disjoint regions of the
directory entry cache.rcu_ctrlblk.lock, protects a small, global control structure used to
manage work for a Read-copy update (RCU). When this lock is held, only a
subset of the structure's 4 integers and per-CPU bitmap are modified
and the lock is immediately released. Our experimental data closely
follows this pattern, with the lock's critical sections accessing an
average of 7 bytes, 5 of which conflict.zone.lru_lock
protects two linked lists of pages that are searched to identify page
frames that can be reclaimed. Replacing the linked list with a data
structure that avoided conflicts on traversal could substantially
increase the level of data independence.
Lock Total Acquires Contended Acq Data Conflicts Mean Addr Set Bytes Mean Confl Bytes zone.lock 14,450 396 (2.74%) 100.00% 161 50 ide_lock 4,669 212 (4.54%) 97.17% 258 24 runqueue_t.lock (0xc1807500) 4,616 143 (3.23%) 84.62% 780 112 zone.lru_lock 16,186 131 (0.81%) 48.09% 134 8 rcu_ctrlblk.lock 10,975 84 (0.77%) 97.62% 27 4 inode.i_data.i_mmap_lock 1,953 69 (3.53%) 89.86% 343 48 runqueue_t.lock (0xc180f500) 3,686 62 (1.74%) 90.32% 745 118 runqueue_t.lock (0xc1847500) 2,814 27 (0.96%) 88.89% 530 74 runqueue_t.lock (0xc1837500) 2,987 24 (0.80%) 95.83% 526 100 runqueue_t.lock (0xc184f500) 3,523 22 (0.68%) 86.36% 416 70 runqueue_t.lock (0xc182f500) 2,902 24 (0.83%) 87.50% 817 103 runqueue_t.lock (0xc1817500) 3,224 17 (0.68%) 94.12% 772 108 runqueue_t.lock (0xc1857500) 2,433 20 (0.86%) 90.00% 624 100 dcache_lock 15,358 21 (0.14%) 0.00% 0 0 files_lock 7,334 20 (0.27%) 70.00% 15 8
Table 2: The fifteen most contended spin locks during the pmake benchmark. Total Acquires is the number of times the lock was acquired by a process. Different instances of the same lock are distinguished by their virtual address. Contended Acq is the number of acquires that required a process had to spin before obtaining the lock, including the percent of total acquires. The Data Conflicts column lists the percentage of Contended Acquires that had a data conflict. Mean Addr Set Bytes is the average address set size of conflicting critical sections, whereas Mean Confl Bytes is the average number of conflicting bytes.
seqlock_t.lock. Seqlocks are a kernel synchronization primitive
that provides a form of optimistic concurrency by allowing readers to
speculatively read a data structure. Readers detect concurrent
modification by checking a sequence number before and after reading.
If the data structure was modified, the readers retry. Seqlocks use a
spinlock internally to protect against concurrent increments of the
sequence number by writers, effectively serializing writes to the
protected data. Because the same sequence number is modified every
time the lock is held, this lock's critical section will never be data
independent. Although this seems to limit concurrency at first blush,
there remains a great deal of parallelism in the construct because an
arbitrarily large number of processes can read the data protected by
the seqlock in parallel. Sometimes locks that protect conflicting
data sets are not indicators of limited concurrency because
they enable concurrency at a higher level of abstraction.tvec_base_t from
an occasional access by another CPU tend to have an extremely low
degree of data independence because they are fine grained. In the
common case, however, the data these locks protect is only accessed by
one CPU, which represents a large degree of overall concurrency. We
leave extending this methodology to multiple levels of abstraction for
future work.
Lock Confl Acq Mean Confl Bytes zone.lock 100.00% 32.49 20.40% zone.lru_lock 65.82% 6.63 20.10% ide_lock 70.92% 6.93 19.03% runqueue_t.lock (0xc1807500) 27.41% 24.06 24.50% runqueue_t.lock (0xc180f500) 29.14% 26.10 23.20% inode.i_data.i_mmap_lock 46.03% 22.81 16.53% runqueue_t.lock (0xc1837500) 27.30% 27.83 19.15% seqlock_t.lock 100.00% 56.01 48.41% runqueue_t.lock (0xc1847500) 23.32% 26.64 19.55% runqueue_t.lock (0xc183f500) 21.03% 28.21 18.37%
Table 3: Limit study data from the ten longest held kernel spin locks during the pmake benchmark. This data is taken from comparing each address set to the last 128 address sets for that lock, rather than contended acquires, as in Table 2. Conflicting Acquires are the percent of acquires that have conflicting data accesses. Mean Conflicting Bytes shows the average number of conflicting bytes and their percentage of the total address set size.
4.3 Transactional Memory
To provide a comparison between the performance of lock-based synchronization and optimistic synchronization, we ran the pmake benchmark under syncchar on both Linux and on TxLinux with the MetaTM hardware transactional memory model [13]. TxLinux is a version of Linux that has several key synchronization primitives converted to use hardware transactions. Syncchar measures the time spent acquiring spinlocks and the time lost to restarted transactions. For this workload, TxLinux converts 32% of the spinlock acquires in Linux to transactions, reducing the time lost to synchronization overhead by 8%. This reduction is largely attributable to removing cache misses for the spinlock lock variable. The syncchar data indicates that converting more Linux locks to transactions will yield speedups that can be exploited by 4–8 processors. However, gaining even greater concurrency requires data structure redesign.
5 Related work
This paper employs techniques from parallel programming tools to evaluate the limits of optimistic concurrency. There is a large body of previous work on debugging and performance tuning tools for programs [3, 15]. Our work is different from other tools because it is concerned more with identifying upper bounds on performance rather than performance tuning or verifying correctness.
Lock-free (and modern variants like obstruction-free) data structures are data-structure specific approaches to optimistic concurrency [4, 5]. Lock-free data structures attempt to change a data structure optimistically, dynamically detecting and recovering from conflicting accesses.
Transactional memory is a more general form of optimistic concurrency that allows arbitrary code to be executed atomically. Herlihy and Moss [6] introduced one of the earliest Transactional Memory systems. More recently, Speculative Lock Elision [10] and Transactional Lock Removal [11] optimistically execute lock regions transactionally. Several designs for full-function transactional memory hardware have been proposed [2, 8, 12].
6 Conclusion
This paper introduces a new methodology and tool for examining the potential benefits of optimistic concurrency, based on measuring the data independence of critical section executions. Early results indicate that there is sufficient data independence to warrant the use of optimistic concurrency on smaller multiprocessors, but data structure reorganization will be necessary to realize greater scalability. The paper motivates more detailed study of the relationship of concurrency enabled at different levels of abstraction, and the ease and efficacy of data structure redesign.
7 Acknowledgements
We would like to thank the anonymous reviewers, Hany Ramadan, Christopher Rossbach, and Virtutech AB. This research is supported in part by NSF CISE Research Infrastructure Grant EIA-0303609 and NSF Career Award 0644205.
References
- 1
- Michael Feldman. Getting serious about transactional memory. HPCWire, 2007.
- 2
- L. Hammond, V. Wong, M. Chen, B. Carlstrom, J. Davis, B. Hertzberg, M. Prabhu, H. Wijaya, C. Kozyrakis, and K. Olukotun. Transactional memory coherence and consistency. In ISCA, 2004.
- 3
- J. Harrow. Runtime checking of multithreaded applications with visual threads. In SPIN, pages 331–342, 2000.
- 4
- M. Herlihy. Wait-free synchronization. In TOPLAS, January 1991.
- 5
- M. Herlihy, V. Luchangco, and M. Moir. Obstruction-free synchronization: Double-ended queues as an example. In ICDCS, 2003.
- 6
- M. Herlihy and J. E. Moss. Transactional memory: Architectural support for lock-free data structures. In ISCA, May 1993.
- 7
- P.S. Magnusson, M. Christianson, and J. Eskilson et al. Simics: A full system simulation platform. In IEEE Computer vol.35 no.2, Feb 2002.
- 8
- K. E. Moore, J. Bobba, M. J. Moravan, M. D. Hill, and D. A. Wood. LogTM: Log-based transactional memory. In HPCA, 2006.
- 9
- C. Papadimitriou. The serializability of concurrent database updates. J. ACM, 26(4):631–653, 1979.
- 10
- R. Rajwar and J. Goodman. Speculative lock elision: Enabling highly concurrent multithreaded execution. In MICRO, 2001.
- 11
- R. Rajwar and J. Goodman. Transactional lock-free execution of lock-based programs. In ASPLOS, October 2002.
- 12
- R. Rajwar, M. Herlihy, and K. Lai. Virtualizing transactional memory. In ISCA. 2005.
- 13
- H.E. Ramadan, C.J. Rossbach, D.E. Porter, O.S. Hofmann, A. Bhandari, and E. Witchel. MetaTM/TxLinux: Transactional memory for an operating system. In ISCA, 2007.
- 14
- J. G. Steffan, C. B. Colohan, A. Zhai, and T. C. Mowry. A scalable approach to thread-level speculation. In ISCA, 2000.
- 15
- Y. Yu, T. Rodeheffer, and W. Chen. Racetrack: Efficient detection of data race conditions via adaptive tracking. In SOSP, 2005.
- Note 1
- We selected the term data conflicts over data dependence to avoid confusion with other meanings.
This document was translated from LATEX by HEVEA.