


to COMP 205 Homework 2 Jan 21, 1998, Due: Jan. 28, 1998
Problems
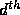 order polynomial
order polynomial 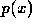 :
:
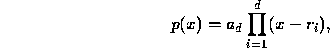
where 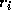 is a root and
is a root and 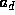 is the coefficient of the high-order term.
Consider the following procedure for evaluating the polynomial:
is the coefficient of the high-order term.
Consider the following procedure for evaluating the polynomial:

Show that the relative error in evaluating a value is:
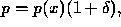 where
where
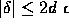 .
.
Solution:
We make the assumption that
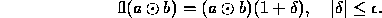
where 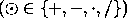 , and where
, and where  is our machine epsilon. Then our
computed value
is our machine epsilon. Then our
computed value 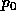 is
is
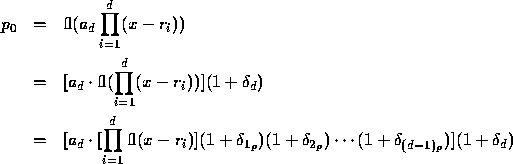
where the 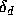 is the relative error on the product with
is the relative error on the product with 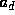 , and the
, and the 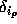 are the
errors for each of the d - 1 products in the product term. Further, for each difference, we have
are the
errors for each of the d - 1 products in the product term. Further, for each difference, we have
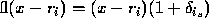 , so our computed value is
, so our computed value is
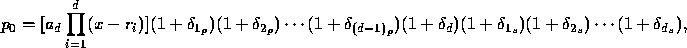
and if we don't differentiate between the different 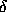 s, this gives
s, this gives

and by our linear approximation,
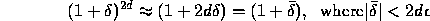
which gives the relative error bound we sought.
 linear system of
equations:
linear system of
equations:
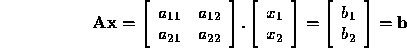
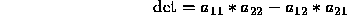
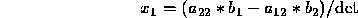
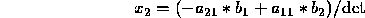
Show by means of a numerical example that Cramer's rule is not backward
stable. Hint: choose the matrix nearly singular and 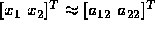 .
Your numerical example can be done by hand on paper (for
example with 4 decimal digit floating point), on a computer, or a hand
calculator. You should clearly explain why Cramer's rule is not backward
stable. Is Cramer's rule forward stable?
.
Your numerical example can be done by hand on paper (for
example with 4 decimal digit floating point), on a computer, or a hand
calculator. You should clearly explain why Cramer's rule is not backward
stable. Is Cramer's rule forward stable?
Solution:
The key here is to see that it is the determinant computation and its possibility for catastrophic cancellation and loss of significant digits that renders Cramer's rule a bad method for linear system solving. We will chose a matrix which is nearly singular, but still well enough conditioned that Gaussian elimination with pivoting can find a good approximate answer, and see how poorly Cramer's rule can perform. Consider the linear system
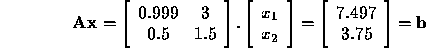
This has the exact solution 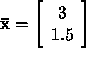 and using Gaussian elimination with pivoting, with 4-decimal floating point, we can compute
this answer accurately. Using Cramer's rule, however, we compute
and using Gaussian elimination with pivoting, with 4-decimal floating point, we can compute
this answer accurately. Using Cramer's rule, however, we compute
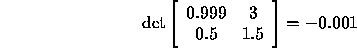
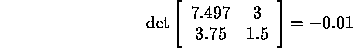
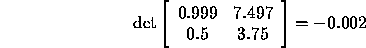
From these, we compute 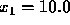 and
and 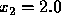 . We can see right away that the forward
error is rather awful. To compute the backward error, we consider this new
. We can see right away that the forward
error is rather awful. To compute the backward error, we consider this new 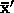 to
be the correct solution, and seek the perturbed problem that it solves exactly. We can keep
to
be the correct solution, and seek the perturbed problem that it solves exactly. We can keep
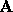 fixed and simply compute a new
fixed and simply compute a new 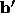 by
by
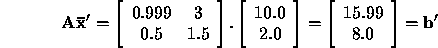
This gives a relative backward error (using the 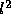 vector norm) of
vector norm) of
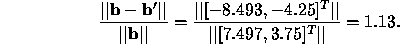
 would not solve the
asymmetry problem. Try to explain your answer geometrically. (10 points)
would not solve the
asymmetry problem. Try to explain your answer geometrically. (10 points)
Solution:
The key to understanding the asymmetry lies in visualizing the test that's taking place.
A point of intersection between two of the lines is computed, and then this is tested
against each of the other two lines in turn, to see if it lies within  of that
line. This gives us an accept-region of width
of that
line. This gives us an accept-region of width 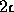 about each of the
two lines, and the intersection of the accept-regions is the area within which our test
will return INTERSECT. Since the shape/area of this INTERSECT region will depend on
the angle between the lines and on their orientation, use of such a test clearly leads
to an algorithm which depends on which pair of lines is chosen. (See diagrams on next page)
about each of the
two lines, and the intersection of the accept-regions is the area within which our test
will return INTERSECT. Since the shape/area of this INTERSECT region will depend on
the angle between the lines and on their orientation, use of such a test clearly leads
to an algorithm which depends on which pair of lines is chosen. (See diagrams on next page)
 . (10 points)
. (10 points)
Solution:
There are a number of correct ways to eliminate asymmetric dependence of test results on the order of the input.
 . This eliminates
both input asymmetries and test inconsistences, at the cost of six intersection
computations rather than one.
. This eliminates
both input asymmetries and test inconsistences, at the cost of six intersection
computations rather than one.
 , return an INTERSECTION.
This requires only 3 intersection computations rather than six. One might chose the
line most orthogonal to the other 3 for the test line, to achieve the most stable result.
, return an INTERSECTION.
This requires only 3 intersection computations rather than six. One might chose the
line most orthogonal to the other 3 for the test line, to achieve the most stable result.

Figure 1: Accept-region intersections of width 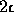 between two lines.
between two lines.
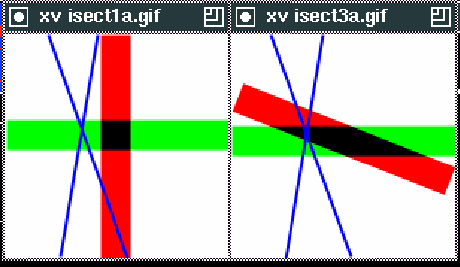
Figure 2: Ambiguous test results of lines with unaltered intersection points.