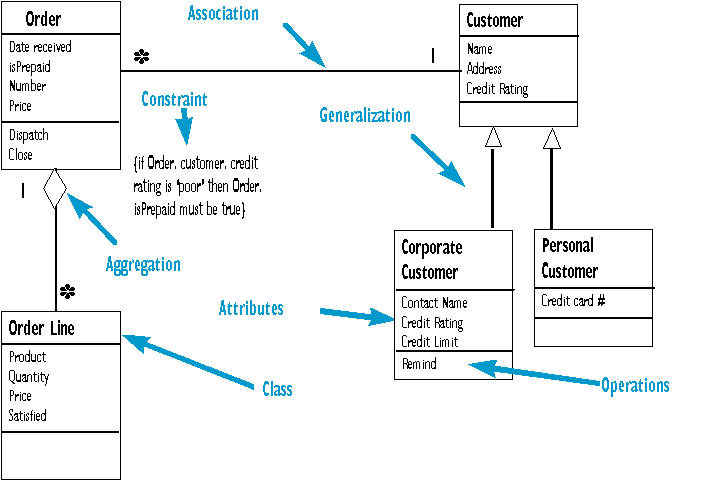
The class diagram is a central modeling technique that runs through nearly all object-oriented methods. This diagram describes the types of objects in the system and various kinds of static relationships which exist between them. There are three principal kinds of relationships which are important: associations (a customer may rent a number of videos), subtypes (a nurse is a kind of person) and aggregation (an engine is part of an aircraft). The various OO methods all use different (and often conflicting) terminology for these concepts, this is extremely frustrating but inevitable: OO languages are just as inconsiderate. It is in this area that the UML will bring some of its greatest benefits in simplifying these different diagrams. In this section I will use the UML terms as my main terminology, and relate to other terms as I go along.
Before I begin describing class diagrams I have to bring out an important subtlety in the way that people use class diagrams. This is a subtlety that is usually undocumented, but has an important impact on the way you should interpret a diagram, for it really concerns what it is you are describing with a model. Following the lead of [Cook and Daniels] I say that there are three perspectives you can use in drawing class diagrams (or indeed any model, but it is most noticeable in class diagrams).
Understanding the perspective is crucial to both drawing and reading class diagrams. As I talk about the technique further I will stress how each element of this technique depends heavily on the perspective. When you are drawing a diagram, draw it from a single clear perspective, when you read a diagram make sure you know which perspective the drawer drew it in. That knowledge is essential if you are to interpret the diagram properly. Unfortunately the lines between the perspectives are not sharp, and most modelers do not take care to get their perspective sorted out when they are drawing.
UML, on the whole, takes an implementation perspective, although its use of associations is often more conceptual than implementation. Most authors follow the same route. Odell is a notable exception for he is relentlessly conceptual. Shlaer/Mellor are also much more conceptual and their translation approach to development will often cause a significant change from diagram to implementation.
| UML | Booch | Coad | Jacobson | Odell | Shlaer/ Mellor | Rumbaugh |
| Class | Class | Class & Object | Object | Object Type | Object | Class |
| Association | uses | Instance Connection | Acquaintance association | Association | Relationship | Association |
| Generalization | inherits | Gen-Spec | inherits | Subtype | Subtype | Generalization |
| Aggregation | containing | Part-Whole | Consists of | Composition | None | Aggregation |
Associations represent relationships between instances of types (a person works for a company, a company has a number of offices…). The interpretation of them varies with the perspective. Conceptually they represent conceptual relationships between the types involved. In specification these are responsibilities for knowing, and will be made explicit by access and update operations. This may mean that a pointer exists between order and customer, but that is hidden by encapsulation. A more implementation interpretation implies the presence of a pointer. Thus it is essential to know what perspective is used to build a model in order to interpret it correctly.
Associations may be bi-directional (can be navigated in either direction) or uni-directional (can be navigated in one direction only). Conceptually all associations can be thought of as bi-directional, but uni-directional associations are important for specification and implementation models. For specification models bi-directional associations give more flexibility in navigation but incur greater coupling. In implementation models a bi-directional association implies coupled sets of pointers, which many designers find difficult to deal with. The various books all make different choices about directions. For example Shlaer/Mellor and Odell use bi-directional associations, Jacobson uses uni-directional associations, Booch, Rumbaugh, and the UML tend to use bi-directional in analysis but uni-directional in design (although that is not a hard and fast rule). Often those who use bi-directional associations have notation to indicate a uni-directional association when needed. With a bi-directional association the word role (or mapping in Odell) represents a single direction. Thus a bi-directional association has two roles but a uni-directional association would have only one.
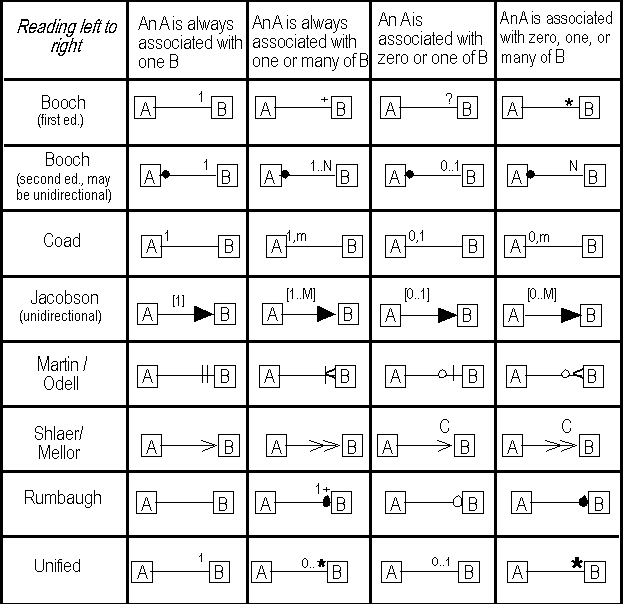
One of the key aspects of associations is the cardinality of an association (sometimes called multiplicity). This specifies how many companies a person may work for, how many children a mother can have, etc. This corresponds to the notion of mandatory, optional, 1-many, many-many relationships in the Entity-Relationship approach. Each method uses a particular notation to indicate the cardinality: it is a sad fact that they are all completely different. Hopefully the UML style will become prevalent. The cardinality is specified for each role in the association. Figure 1 shows the common cardinalities from the major methods. Other cardinality bounds than the four shown (such as a meeting having a lower bound of two) can appear but are rare.
A long dispute in data modeling is the question of the difference between attributes and associations. Attributes are seen as internal to a class whilst associations link classes. It is also said that attributes refer to values (i.e. non-objects) whilst associations link to classes. Data modeling has long wrestled with the question of what the difference between the two is, this question is made more relevant with object methods. Most methods, including the UML, do not give a precise distinction between the two. Booch considers attributes equivalent to a uni-directional association which is implemented by containment in C++. Odell considers the difference to be purely one of notation. OO methods typically show attributes within the class symbol, which is useful providing the list is not long. Operations are usually also listed within the class box.
Aggregation relationships are introduced by many methods. These indicate part/whole relationships (e.g. a hammer is made up of a head and a haft). It is notoriously difficult to define the difference between an aggregation and an association, or to indicate whether the distinction is useful. When guidelines are provided they are not consistent with other methods. Thus you should be particularly cautious of aggregation when moving from one method to another. Implementation perspectives often use aggregation to imply C++ containment. [Odell foundations] discusses how combinations of three properties an association yield different kinds of aggregation. Many of the different views of aggregation are based on which combinations they accept as valid for aggregation.
Rumbaugh and Odell introduced the notion of derived (or computed) associations. These describe how associations can be defined based on other base associations (thus grandfather is an association defined by running the parent association followed by the father association.) This concept can be further extended to bring in derived types, attributes and subtypes. It can be used to define queries, views, and higher level constraint rules.
Rumbaugh and Shlaer/Mellor have association classes which allow associations to have attributes and operations. Both Odell and Rumbaugh allow associations to be subtyped just like types which define how subtypes can place further constraints on inherited associations.
Conventionally it is assumed that multi-valued associations are sets (i.e. the children of a person is a set of people). The UML, Odell and Rumbaugh provides notations for supporting other kinds of collection. Marking a line with {ordered} (Rumbaugh, UML) or [list] (Odell) indicates a list rather than a set. A qualified allows the set to have a lookup key (such as directory: file name) which is a useful conceptual notion of what OO languages support with dictionaries (also called: hash tables, maps, and associative arrays).
Subtyping is the most obvious addition to ER diagrams for use in OO. It has an immediate correspondence to inheritance in OO programming. However the object-oriented community should not forget that subtyping has been around in data modeling long before the object cavalry rode over the horizon.
A typical example of subtyping is to consider personal and corporate customers of a business. They have differences but also many similarities. The similarities can be placed in a general customer class with personal and corporate customer as subtypes.
Again this phenomenon has different interpretations at the different levels of modeling. Conceptually we can say that corporate customer is a subtype of customer if all instances of corporate customer are also, by definition, instances of customer. From a specification model we would say that the interface of corporate customer must conform to the interface of customer. That is an instance of corporate customer may be used in any situation where a customer is used, and the caller need not be aware that a subtype is actually present (the principle of substitutability). The corporate customer may respond to certain commands differently than another customer (polymorphism) but the caller should not need to worry about the difference.
Inheritance and subclassing in OO languages is an implementation approach. It says that the subclass inherits the data and operations of the superclass. It has a lot in common with subtyping, but there are important differences. Subclassing is only one way of implementing subtyping (see [Odell pragmatics] or [Fowler]). Subclassing may also be used without subtyping and most authors frown upon this practice. Newer languages and standards increasingly try to emphasize the difference between interface-inheritance (subtyping) and implementation-inheritance (subclassing).
Classification is the relationship between an object and its type. Odell introduced the distinction between single and multiple classification. In single classification an object has a single class, which may inherit from super-classes. In multiple classification it may it have several classes which are not connected by inheritance. Note that multiple classification is different to multiple inheritance. Multiple inheritance says a type may have many supertypes, but a single class must be defined for such objects. Multiple classification allows multiple types for an object without defining a specific class for the purpose. An example of this is to consider a person subtyped as either man and woman, doctor or nurse, and patient or not. Multiple classification allows an object to have any or these types assigned to it in any allowable combination without types defined for all the legal combinations. Defining the legal combinations is important, of course. Rumbaugh's later work also used this concept which he called parallel generalization. This concept also appears as and-Generalization in the UML.
Another question is whether an object may change its type. A good example here is of a bank account. When it is overdrawn it substantially changes its behavior, with several operations (withdraw, close) overridden. Dynamic classification allows objects to change type within the subtyping structure whilst static classification does not. With static classification a separation is made between types and states: dynamic classification combines these notions.
The mainstream OO languages have static, single classification. OO methods initially followed this approach. Odell was one of the strongest advocates of a multiple, dynamic approach. Methods make a number of variations on this theme. Booch follows the single, static approach. Rumbaugh introduced parallel Generalization and also introduced state-classes for dynamic classification.. Shlaer/Mellor use subtype-migration to represent dynamic classification. Jacobson uses an inherits relationship for single static classification and also has an extends relationship which seems to be the same thing, but allows multiple and dynamic classification. The UML's stance is to use single, static classification as the usual sense, but to easily allow multiple and dynamic classification if needed.
One area of OO analysis and design that has gained more attention in recent years is that of rules. The general notion is to apply the ideas of AI on rule based systems into OO modeling. Actually some of these have been around for a while in the object community. Eiffel has long had support for assertions as part of its principle of Design by Contract, which been sadly neglected in many OO methods. In the structural view the principal assertion is the constraint. This is a logical expression about a type which must always be true. Cardinality express some constraints, but not all. Rumbaugh and the UML use the brace {} notation to show constraints on the structural model.
A wider view of rules allows other inference like structures. The two strongest books in this area are [Odell foundations] and [Graham]. [Odell foundations] discusses both structural and behavioral rules and how they can be defined. [Graham] adds rules to the structural model and discusses many AI principals. In addition he adds a discussion on fuzzy rules. Many later methods, especially those from the UK and Europe, show a greater following for the principles of Meyer's design by contract as embodied in Eiffel; [Waldén and Nerson], and [Cook and Daniels] are good examples.
Class diagrams are the backbone of nearly all OO methods so you will find yourself using them all the time. The trouble is that they are so rich that they can be overwhelming to use. Here are a few tips:
The biggest danger with class diagrams is that you can get bogged down in implementation details far too early. To combat this use the conceptual or specification perspective. If you get these problems you may well find CRC cards to be extremely useful.
At the moment my advice depends on whether you prefer an implementation
or a conceptual perspective. For an implementation perspective
try [Booch], for a conceptual
perspective try [Odell foundations].
Once you have read your choice read the other one. Both perspectives
are important. After that any OO book will add some interesting
insights. I particularly like [Cook and Daniels]
for its treatment of perspectives and the formality that they
introduce.