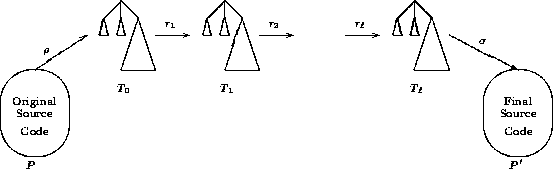Domain specific languages (DSL) can often be implemented as a source-to-source translator composed with a processor for another language. For example, PIC [8], a classic ``little language'' for typesetting figures, is translated into troff, a general-purpose typesetting language. Language composition can be extended in either direction: the CHEM language [1], a DSL used for drawing chemical structures, is translated into PIC, while troff is commonly translated into PostScript.
Other DSLs translate into general-purpose high-level programming languages. For example, ControlH, a DSL for the domain of real-time Guidance, Navigation, and Control (GN&C) software, translates into Ada [5]; and RISLA, a DSL for financial engineering, translates into COBOL [18].
The composition of a DSL processor with (for example) a C compiler is attractive because it provides portability over a large class of architectures, while achieving performance through the near universal availability of architecture-specific optimizing C compilers.
Yet there are some drawbacks to this approach. While DSLs are often simpler than general purpose programming languages, the domain-specific information available may result in a generated program that can be much larger and substantially different in structure than the original code written in the DSL. This can make debugging very difficult: an exception raised on some line of an incomprehensible C program generated by the DSL processor is a long way removed in abstraction from the DSL input program.
Since the DSL processor is composed with a native high-level compiler, and does not have to perform machine-code generation or optimization, we believe that there are some basic differences between the construction of a compiler for a general purpose programming language and the construction of a translator for a DSL. Our view is that DSL translation is most simply expressed as
For the translation step we advocate the use of arbitrary AST traversals and transformations. We believe that this approach is simpler for source-to-source translation than the use of attribute grammars, since it decouples the AST analysis and program synthesis from the grammar of the input and output languages. Further, this approach minimizes the need for parsing ``heroics'', since simple grammars, close or identical to the natural specification of the DSL syntax, can be used to generate an AST that is specialized in subsequent analysis. By decoupling the input grammar, translation process, and output grammar, this approach is better able to accommodate changes during the evolution of the DSL syntax and semantics.
Throughout this paper, we will use ``AST'' to refer to abstract syntax tree derived from parsing the input file, and to any intermediate tree-based representations derived from this original AST, even if those representations do not strictly represent an ``abstract syntax''.
In our own work we use the DSL paradigm in the compilation of parallel programs. We are particularly interested in the translation into HPF of irregular computations expressed in the PROTEUS [12] language, a DSL providing specialized notation. Our observation was that we were spending a disproportionate amount of effort working on a custom translator implementation to incorporate changes in PROTEUS syntax and improvements in the translation scheme--thus we were motivated to investigate general tool support for DSL translation to simplify this process.
The implementation of a DSL translator can require considerable overhead, both for the initial implementation and as the DSL evolves. A toolkit should leverage existing, familiar tools as much as possible. Use of such tools takes advantage of previous implementor knowledge and the availability of comprehensive resources explaining these tools (which may not be widely available for a DSL toolkit).
A transformational model for DSL design fits in well with these high-level
goals. Consider the problem of translating a program, P, written in the
domain specific language, L. In Figure 1, T0 is an AST which
represents P after the parsing phase, ![]() . Tl is the final
transformed AST, and P' is a valid program in the output language, L',
constructed from Tl during the pretty-printing phase,
. Tl is the final
transformed AST, and P' is a valid program in the output language, L',
constructed from Tl during the pretty-printing phase, ![]() . The
transformation process is viewed as a sequential application of various
transformations functions,
. The
transformation process is viewed as a sequential application of various
transformations functions, ![]() , to the AST. The
determination of which transformation function to apply next may require
extensive analysis of the AST. Once the transformation functions are
determined, however, they can be rapidly applied for replay or debugging.
, to the AST. The
determination of which transformation function to apply next may require
extensive analysis of the AST. Once the transformation functions are
determined, however, they can be rapidly applied for replay or debugging.
Within a transformational model, a DSL-building toolkit can simplify the implementation process by providing specialized tools where pre-existing tools are not already available, and to transparently integrate support for debugging within this framework.
The KHEPERA system facilitates both the problem of rapid DSL prototyping and the problem of long-term DSL maintenance through the following specific design goals: