My Papers & Projects
2013
Abstract:
This paper describes GPUSync, which is a framework for managing graphics processing units (GPUs) in multi-GPU multicore real-time systems. GPUSync was designed with flexibility, predictability, and parallelism in mind. Specifically, it can be applied under either static- or dynamic-priority CPU scheduling; can allocate CPUs/GPUs on a partitioned, clustered, or global basis; provides flexible mechanisms for allocating GPUs to tasks; enables task state to be migrated among different GPUs, with the potential of breaking such state into smaller “chunks”; provides migration cost predictors that determine when migrations can be effective; enables a single GPU's different engines to be accessed in parallel; properly supports GPU-related interrupt and worker threads according to the sporadic task model, even when GPU drivers are closed-source; and provides budget policing to the extent possible, given that GPU access is non-preemptive. No prior real-time GPU management framework provides a comparable range of features.
G. Elliott, B. Ward, and J. Anderson, "GPUSync: A Framework for Real-Time GPU Management." Proceedings of the 35th Real-Time Systems Symposium (RTSS), December 2013.
Copy of paper available here. Full version with appendix.
Source code here.
(The material behind this paper was developed over the course of a year and a half of research. Not all of our results could be put in a single paper. Other information on GPUSync, such as memory transmission costs to GPUs and the effects on the system memory bus, can be found here.)
GPUSync: A Framework for Real-Time GPU Management
9/23/13
GPUSync extends the LitmusRT Linux kernel patch, adding over 20k lines of code to support a myriad of reconfigurable and adaptive multi-GPU scheduling algorithms.
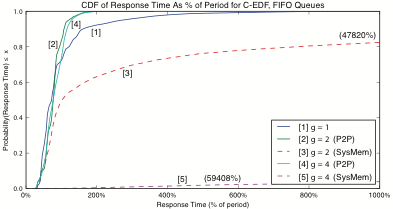
Left: Cumulative distribution functions of video frame response times in a computer vision application that processes 30 video streams simultaneously. Under the tested configuration, clustered GPU scheduling (lines 2 and 4) outperform a traditional partitioned approach (line 1).