Decomposing an application into multiple threads is important in single-user applications since it allows these threads to execute simultaneously on a multiprocessor system. It is particularly important in multimodal applications where the devices for different I/O modes such as audio, video, mouse, and keyboard can be managed by different threads. The multiuser case offers additional opportunities and reasons for creating multiple threads. Typically, the users of a collaborative application can input and output data concurrently. Thus, the different branches created for these users are potential concurrency units that can be executed simultaneously by different processors of a multiprocessor system. Even in a single-processor system, creating separate threads for these branches is important. It supports fair (preemptive) scheduling among these threads by ensuring that a computation triggered in a branch by the actions of a user does not lock out other users for an unbounded time.
However, there are reasons why a complete branch may not be associated with its own thread. The system support needed to create threads may not be available to programmers. Moreover, programmers may not be willing to put the effort required to create and synchronize threads. A collaboration tool can automate this task for the layers it knows about but not those in its clients. Similarly, it may not be possible to assign a thread to a layer without requiring changes to the layer since the syntax and semantics of an invocation in the same or different thread may be different. Thus, the goal of increasing the concurrency may conflict with the goal of reuse since the former may require changes to source code of an existing layer.
As a result, different architectures may take different approaches to concurrency depending on how they tradeoff the benefits of concurrency with its drawbacks. To capture differences among these architectures, we associate them with a concurrency degree, which is a measure of how many layers in a branch execute in their own thread. An architecture has concurrency degree, C, if no layer at or below level C shares a thread with a stem layer or a layer in a different branch. Different layers in a branch may, and typically do, share a common thread. The concurrency degree of a collaboration architecture ranges from 0 to R, where R is its replication degree. We refer to architectures with concurrency degree 0 and R as sequential and concurrent architectures, respectively, and the remaining architectures as semi-concurrent architectures (Figure 9.8) . A sequential architecture must be a centralized architecture. In a non-centralized architecture, the workstation level is guaranteed to be replicated. A replicated workstation level (but not other levels) must be distributed, by definition, since a level is distributed if it resides on multiple workstations. Furthermore, we assume that distributed layers execute concurrently. Hence no non-centralized architecture is sequential.
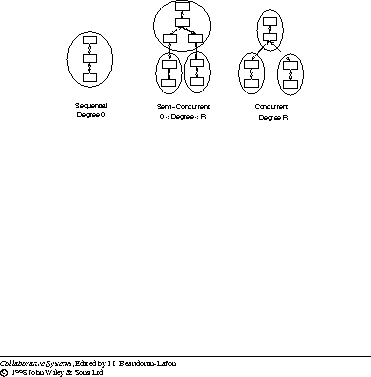
Figure 9.8: Concurrency approaches. The rectangular boxes are layers and the ellipses are threads.
All collaboration tools known to us offer the concurrent approach. Of course, the replication degrees in these systems may be different, as mentioned before, which causes variations in the concurrency offered by them. For instance, the concurrency degree in Rendezvous and Suite is 4 and in XTV it is 2. In all existing replicated architectures it is the same as the layering -- and hence replication -- degree.
The above discussion identifies a simple approach to introducing concurrency in a collaborative application: assign all branch layers below some level C to a separate thread. A concurrent architecture created using this approach does not necessarily offer the maximum possible concurrency, which would require an approach that identifies all portions of the application that could potentially execute concurrently and assigns each of these to a separate thread. We refer to such an approach as the maximal-concurrent approach. This approach is highly application dependent and either requires the programmer to identify the threads, which has proven to be a tedious, error-prone, and difficult task in general, or the system to automatically perform this task, which in general is impossible. Unlike the maximal-concurrent approach, our approach does not process concurrently the actions in a branch or stem invoked by a single-user (such as concurrent mouse and key clicks by the same user), or the actions in the stem invoked by different users (such as concurrent key clicks by two independent users handled by a central layer). However, it does allow the computation of the local feedback in the branches of different users to be performed concurrently.
Note that the notion of the concurrency degree applies to all collaboration architectures including those that assign threads based on approaches other than the one we have given above. However, it does not capture all concurrency differences among these architectures. For instance, as mentioned above, a concurrent architecture may or may not be a maximal concurrent architecture.