Once the threads of an application have been identified, they must be assigned to process address spaces, which in turn must then be assigned to hosts. Assigning different threads to multiple address spaces increases fault tolerance since fatal errors in one thread do not necessarily cause the whole application to fail. This is particularly important in the multiuser case, since users would like to be protected from the errors of others. If the replicas created for different users are assigned to different address spaces, then a fatal error in one replica would not necessarily cause the other replicas to crash.
Distributing different processes to different hosts also allows an address space to be close to the resources it is accessing the most. Again, this is particularly important in the multiuser case, since the replicas created for different users need to access different and possibly widely separated workstations. By executing replicated layers on a local workstation, no remote communication is required to generate the local feedback computed by these layers. Moreover, events transmitted from these workstations are high-level events generated by the local layers rather than low-level events generated by the workstation. Typically, a higher-level I/O event contains less data and is communicated less frequently than a lower-level one, and thus generates less traffic on the network. For instance, communicating committed changes to an integer value communicates less data than communicating incremental changes to a slider representation of it.
On the other hand, distributing portions of an application on different workstations is not without drawbacks. The distributed parts of the application are not guaranteed to see the same environment, which can cause problems.
For instance, problems would occur if the application uses a file name that is not valid at all sites unless the application is site-aware. Moreover, synchronizing distributed replicas is a difficult problem. Often an event received by a layer must also be sent to remote replicas to satisfy consistency constraints among them. To ensure good response times for the local users, such events must be processed immediately by the local layers without trying to ensure a global ordering among them. As a result, the distributed replicas may get inconsistent unless application-specific techniques [EG89] are used to transform or abort received events, or the events are guaranteed to commute.
As a result, different architectures take different approaches to distribution depending on how they tradeoff its communication benefits with its drawbacks. To capture differences among these architectures, we associate an architecture with a distribution degree, which is analogous to its concurrency degree. It is a measure of how many layers in a branch can execute on the local host. An architecture has distribution degree, D, if no layer at or below level D shares an address space with a stem layer or a layer in a different branch. Different layers in a branch may, and typically do, share a common address space. The concurrency degree of a system is always higher than its distribution degree since distributed modules execute concurrently. However, it is not the same, since a particular address space can execute multiple threads concurrently. Thus, the distribution degree of a collaboration architecture ranges from 0 to C, where C is its concurrency degree. We refer to architectures with distribution degree 0 and C as single-site and distributed architectures, respectively, and the remaining architectures as semi-distributed architectures (Figure 9.9). A single-site architecture must be a sequential architecture since distributed modules execute concurrently. Like the maximal-concurrent approach, it is possible to imagine a maximal-distributed approach that dynamically assigns each application module to the workstation accessing it the `most'. However, such an approach [JLHB88] is still a subject of research and requires application-specific support. Our notion of a distribution degree does not distinguish between those distributed architecture that offer maximal distribution and those that do not.
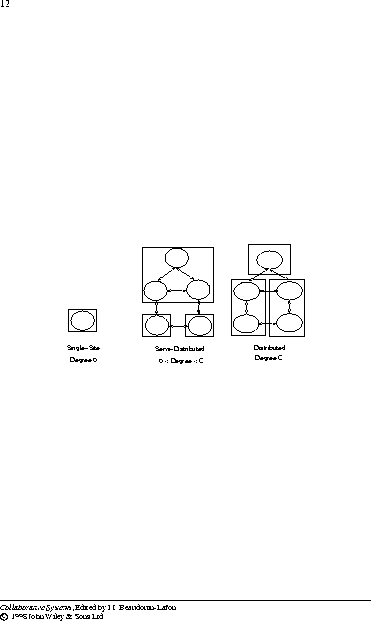
Figure 9.9: Distribution approaches. Ellipses are threads and rectangles are hosts.
The distributed approach determines only how the application is decomposed into processes and not how these processes are assigned to hosts. Depending on the workstation and network speed, it may, in fact, be sometimes beneficial to execute branch layers on a fast remote workstation. The higher the distribution degree of an architecture, the more the flexibility in reducing the communication costs.
Not all communication costs go down when a replica is executed on a local host. In particular, the cost of communicating with remote higher-level and peer layers goes up. However, assuming that information gets abstracted as it flows upwards and that a collaboration or input event received by a layer triggers a lower-level output event, the overall communication cost is reduced. To better understand the logic behind this conclusion, consider Figure 9.10, which shows the difference between placing replicas, A and A', on local and central hosts. Consider how an input IA, to layer A, is processed by the various layers in the architecture. Layer A produces some local feedback, OAL, sends a collaboration event, CA, to its peer, and an input event, IB, to the higher-level layer. The higher-level layer, in turn, produces feedback TOB (which is the total feedback consisting of feedback of B and all of the layers above), which, in turn, is transformed to TOA by layer A. On receiving CA, layer A' produces coupling feedback CAO, and sends an input event IB' to B'. Layer B', in turn, produces total feedback TOB', which, in turn, is transformed by A' to TOA'.
Consider the local and central placement schemes shown in Figure 9.10. The difference between them is in the placement of the replicas - under local placement, replicas A and A' are placed on the local workstations, while under central placement, they are placed on the central site. In the local case, events IA, TOA, CAO, TOA', OAL are transmitted locally, and events IB, TOB, CA, TOB', and IB' are transmitted across the network, while in the central case, the converse is true. If we assume that information gets condensed when it is processed by a higher-level layer, then the following relationships hold among the size of these events: IA > IB, TOA > TOB, CAO > CA, TOA' > TOB'. Also, if we assume that a higher-level event triggered by an input event is smaller than any lower-level event also triggered by the same input, then OAL > IB'. These relationships imply that more information is transmitted locally in the first case.
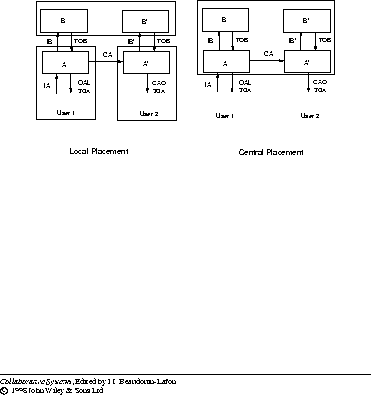
Figure 9.10: Local and central placement of replicated layers.
We have ignored, above, peer collaboration events sent to B' and other layers above A'. In both cases, such events will be communicated locally. However, under local placement, the resulting output sent to the remote user will be higher level - the output of B' rather than A' - thereby further reducing the communication cost.
We have also ignored collaboration events sent to cross layers. For similar reasons, these events also favour local placement of modules.
Most existing architectures offer the distributed approach, that is, distribute all of their concurrent threads.
A notable exception is the Rendezvous architecture, which offers a distribution of degree of 2 but a concurrency degree of 4. In this architecture, all layers except the X window layers execute at a central site. However, at the central site, the layers in different branches execute in separate threads. The Clock system provides a hybrid approach, allowing the same application program to have degrees 2 to 4, depending on whether it centralizes the replicated widget and view layers.
In our discussion above, we have assumed that every collaboration event sent to a peer layer results in an output event. This may not hold true for constraint-based systems such as Rendezvous, Weasel, and Clock, which may need several collaboration events to be exchanged before the constraint evaluation can fire the output events. It is perhaps for this reason that Rendezvous does not use a distributed architecture, though preliminary performance results from Weasel and Clock show advantages of using such an architecture even in a constraint-based environment.