The between two network hosts is defined as the time required to send a packet from one host to another plus the time required to send a packet in the reverse direction. These two times are often very similar, but may sometimes vary considerably (e.g., in the presence of asymmetric routing). In general, round-trip times are not constant, since queuing delays, switching fabric contention, route lookup times, etc., vary over the lifetime of a connection.
Round-trip times play a very important role in TCP connections. As indicated in Chapter 3, the exchange of a request ADU and its response ADU (i.e., an epoch) in a TCP connection requires at least one round-trip time. This is independent of the amount of data exchanged. In addition, the speed at which data can be delivered (known as throughput4.1), is also a function of the round-trip time of the TCP connection.
The minimum time between the sending of a data segment and the arrival of its
corresponding acknowledgment is exactly one round-trip time.
Without TCP's window mechanism, TCP would only be able to send one segment
per round-trip time, since it would have to wait for the acknowledgment before
sending the next data segment. Therefore, peak throughput would be given by
the maximum segment size ![]() divided by the round-trip time
divided by the round-trip time
![]() . This would imply that the longer the round-trip time, the lower the
throughput
. This would imply that the longer the round-trip time, the lower the
throughput ![]() of the connection would be.
In order to increase performance, a TCP endpoint can send
a limited number of segments, a window, to the other endpoint before
receiving an acknowledgment for the first segment. The number of segments
of the connection would be.
In order to increase performance, a TCP endpoint can send
a limited number of segments, a window, to the other endpoint before
receiving an acknowledgment for the first segment. The number of segments ![]() in the window gives the peak throughput of a TCP connection,
in the window gives the peak throughput of a TCP connection, ![]() .
This peak throughput can be lower if the path between the two endpoints
has a capacity
.
This peak throughput can be lower if the path between the two endpoints
has a capacity ![]() that is lower than
that is lower than ![]() , so the peak
throughput of a TCP connection is given by
, so the peak
throughput of a TCP connection is given by
![]() .
This implies that if
.
This implies that if ![]() is not large enough to fill the available capacity
is not large enough to fill the available capacity ![]() ,
,
![]() is the limiting factor in the peak throughput of a TCP connection.
is the limiting factor in the peak throughput of a TCP connection.
A new TCP connection is not allowed to reach its peak throughput until it completes a
``ramp-up'' period known as slow start [Pos81]. The
throughput of TCP during slow-start is also highly dependent on
round-trip time. At the start of each connection, TCP does not make use
of the entire window to send data, but rather probes the capacity of
the network path between the two endpoints by sending an exponentially increasing number
of segments during each round-trip time. This normally means that TCP sends only
1 segment in the first round-trip time, 2 in the second one, 4 in the third one,
and so on, doubling the number of segments after each round-trip time until
this number reaches a maximum of ![]() segments. The throughput of the slow-start phase is therefore
a function of round-trip time and maximum segment size, but it depends little on
receiver window size and capacity. For example, an ADU that fits in 4 segments,
requires 3 round-trip times to be transferred in the slow-start phase
(one segment is sent in the first round-trip time, two in the second one,
and one more in the final one), so the throughput of the connection
is
segments. The throughput of the slow-start phase is therefore
a function of round-trip time and maximum segment size, but it depends little on
receiver window size and capacity. For example, an ADU that fits in 4 segments,
requires 3 round-trip times to be transferred in the slow-start phase
(one segment is sent in the first round-trip time, two in the second one,
and one more in the final one), so the throughput of the connection
is ![]() .
For common values of
.
For common values of ![]() and
and ![]() ,
, ![]() bytes and
bytes and ![]() milliseconds,
the throughput would be 156 Kbps.
This same ADU sent later in the connection using a single window
would achieve a much higher throughput (e.g., the four segments could be sent back to
back, so they would reach the destination after only one half the round-trip time,
milliseconds,
the throughput would be 156 Kbps.
This same ADU sent later in the connection using a single window
would achieve a much higher throughput (e.g., the four segments could be sent back to
back, so they would reach the destination after only one half the round-trip time,
![]() , achieving a throughput of
, achieving a throughput of
![]() Kbps).
Kbps).
The dependency between TCP throughput and round-trip time implies that the distribution of round-trip times of the TCP connections found on a link has a substantial impact on the characteristics of a trace. If we intend to compare the throughputs of connections in traces from real links with those in synthetic traces, traffic generation must employ similar round-trip times. This requires us to be able to extract RTTs from a trace by analyzing packet dynamics. Extracting round-trip times from packet traces has received only limited attention in the literature [JD02,AKSJ03]. Nonetheless we can refine some of the existing ideas to obtain the distribution of round-trip times of connections in a trace in a manner that is useful for traffic generation.
Before we describe several methods for characterizing round-trip times, it is important to point out that the round-trip time of a TCP connection is not a fixed quantity. The time required for a segment to travel from one endpoint to another has several components. Transmission and propagation delays are more or less constant for a given segment size, but queuing delays, medium access contention, and router and endpoint processing, introduce variable amounts of extra delay. The TCP segments observed in our traces are exposed to these delays, whose variability is not always negligible, as our later measurement results illustrate. In summary, the segments of a TCP connection are exposed to a distribution of round-trip times, rather than to a fixed round-trip time.
We can think about the segments of a TCP connection as probes that sample the dynamic network conditions along their path, experiencing variable delays. As shown in the previous chapter, most TCP connections carry a small amount of data, providing only a few samples of these underlying conditions. This makes it very difficult to fully characterize the distribution of round-trip times experienced by an individual connection using only passive measurement methods (i.e., only by looking at packet headers). In addition to the low number of samples per connection, TCP's delayed acknowledgment mechanism adds extra delays to some samples. This introduces even more variability, this time unrelated to the path of the connection. As we discuss below, the presence of delayed acknowledgments makes statistics (such as the mean and standard deviation) computed from RTT samples, grossly overestimate the true mean and standard deviation of the underlying distribution of round-trip times. In our work, we favor more robust statistics, such as the median, or the minimum, which provide a good way of characterizing the non-variable component of a connection's round-trip time. For simplicity, our traffic generation will simulate the minimum round-trip time observed for each connection.
The simplest way of estimating the round-trip time of a connection
from its segment header is to examine the segments sent by the initiator
endpoint during connection establishment. The use of this SYN estimator
is illustrated in Figure 4.1.
The initial SYN segment sent from the initiator to the acceptor is supposed to be
immediately acknowledged by a SYN-ACK segment sent in the opposite direction.
The initiator endpoint would then respond to the SYN-ACK segment4.2with an ACK segment.
The initiator may or may not piggy-back data on this segment,
but this does not affect RTT estimation
significantly. The time between the arrival
of the SYN segment and the arrival of the ACK segment is the round-trip time
![]() of the connection (more precisely, a sample of the round-trip time).
Measuring
of the connection (more precisely, a sample of the round-trip time).
Measuring ![]() using the departure times of the SYN and the ACK segments
from the initiator endpoint gives approximately the same result as measuring
using the departure times of the SYN and the ACK segments
from the initiator endpoint gives approximately the same result as measuring
![]() using the arrivals of these segments at either the monitoring point or the
connection acceptor. In general, the SYN estimator is a good indicator of
the minimum round-trip time, i.e., total transmission and propagation delay. This is because TCP
endpoints respond immediately4.3 to connection establishment segments,
and also because the small packets used by the SYN estimator are less likely
to encounter queuing delays that the larger ones found later in the connection.
The SYN estimator has been a popular means of estimated round-trip times
[AKSJ03,CCG$^+$04].
using the arrivals of these segments at either the monitoring point or the
connection acceptor. In general, the SYN estimator is a good indicator of
the minimum round-trip time, i.e., total transmission and propagation delay. This is because TCP
endpoints respond immediately4.3 to connection establishment segments,
and also because the small packets used by the SYN estimator are less likely
to encounter queuing delays that the larger ones found later in the connection.
The SYN estimator has been a popular means of estimated round-trip times
[AKSJ03,CCG$^+$04].
|
The SYN estimator has a number of shortcomings. First, the estimator provides
a single sample of the round-trip time, which may be a poor representative
of the average round-trip time of the connection. Second, partially-captured
connections in a trace may not include connection establishment segments, so the
SYN estimator cannot be used to determine their round-trip times.
Third, the round-trip time of a connection with a retransmission of the SYN
segment (or of the SYN-ACK segment), cannot be estimated with confidence, since
the coupling of the SYN and the ACK segments becomes ambiguous.
The problem is that the monitor may see two instances of the SYN segment,
and either one could be coupled with the ACK for the purpose of computing the RTT.
This difficulty is illustrated in Figure 4.2.
The left side of the figure shows an example of connection establishment
in which the first SYN segment is lost. In this case ![]() is the time between the
arrival of the second SYN segment and the arrival of the ACK segment, and not
the time between the first SYN segment and the arrival of the ACK segment.
However, it is not always correct to couple the last retransmission of the SYN
with the ACK, and this is illustrated in the right side of the figure.
The diagram shows a connection with such a large
is the time between the
arrival of the second SYN segment and the arrival of the ACK segment, and not
the time between the first SYN segment and the arrival of the ACK segment.
However, it is not always correct to couple the last retransmission of the SYN
with the ACK, and this is illustrated in the right side of the figure.
The diagram shows a connection with such a large ![]() that the initiator endpoint times
out before the receipt of the SYN-ACK and sends an early (i.e., unnecessary)
retransmission of the SYN before the SYN-ACK reaches the initiator.
In this case,
that the initiator endpoint times
out before the receipt of the SYN-ACK and sends an early (i.e., unnecessary)
retransmission of the SYN before the SYN-ACK reaches the initiator.
In this case, ![]() should be computed as the difference between the arrival times
of the first SYN and the ACK, and not between the arrival times of the second SYN and the ACK.
Note that standard TCP implementations time out and retransmit SYN segments
after 3 seconds without receiving an acknowledgment [APS99].
The two cases result in exactly the same sequence of segments observed at the
monitoring point, so it is not generally possible to accurately choose the right
SYN to couple with the corresponding ACK segment by looking only at the sequence of segments
[KP88a,Ste94].
should be computed as the difference between the arrival times
of the first SYN and the ACK, and not between the arrival times of the second SYN and the ACK.
Note that standard TCP implementations time out and retransmit SYN segments
after 3 seconds without receiving an acknowledgment [APS99].
The two cases result in exactly the same sequence of segments observed at the
monitoring point, so it is not generally possible to accurately choose the right
SYN to couple with the corresponding ACK segment by looking only at the sequence of segments
[KP88a,Ste94].
The early retransmission of SYN segments when the RTT is greater than 3 seconds implies that the simple SYN estimator, at least in this basic form, cannot be used to study the tail of the round-trip time distribution (this issue has been overlooked in the literature). In theory, one could disambiguate the case of a timed-out SYN-ACK using the observation that SYN segments are retransmitted only after 3 seconds without receiving the SYN-ACK [Bra89]. However, our empirical observations show that this heuristic is unreliable as the timing of arrivals is imprecise, and not all TCP implementations seem to use the 3-second timeout properly. Detection of an unexpected retransmission of the SYN-ACK (or the ACK) can also be used to develop a heuristic, but cases with multiple losses can be very complicated to disambiguate.
A second technique for estimating round-trip times is
illustrated in Figure 4.3. The location of the
monitor divides the path of a connection into two sides, and we can
estimate the One-Side Transit Time (OSTT) independently for each
side. The sum of the two OSTTs gives an estimate of the round-trip time of
the connection. The idea is that the arrival times of a data segment and its
acknowledgment segment at the monitor provides an estimation of the OSTT from the
measurement point to one of the endpoints.
Round-trip time estimation using the OSTT method requires the collection of
one or more samples of the OSTT between the initiator and the monitoring point,
and one or more samples of the OSTT between the acceptor and the monitoring point.
In Figure 4.3, a sample ![]() of the OSTT for the right side of the path
(i.e., OSTT between the acceptor and the monitoring point)
is given by the difference in the arrival times of segments 2 and 3.
A sample
of the OSTT for the right side of the path
(i.e., OSTT between the acceptor and the monitoring point)
is given by the difference in the arrival times of segments 2 and 3.
A sample ![]() of the OSTT for the left side of the path (i.e., between the initiator
and the monitoring point) is given by the difference in the arrival times of
segments 4 and 5. Thus, a sample of the full round-trip time
of the OSTT for the left side of the path (i.e., between the initiator
and the monitoring point) is given by the difference in the arrival times of
segments 4 and 5. Thus, a sample of the full round-trip time ![]() is given by
is given by ![]() .
One way of seeing this graphically is to do the mental exercise of shifting the monitoring
point toward the initiator. As we do this, the
.
One way of seeing this graphically is to do the mental exercise of shifting the monitoring
point toward the initiator. As we do this, the ![]() increases, while
increases, while ![]() decreases.
When the monitoring point reaches the initiator endpoint,
decreases.
When the monitoring point reaches the initiator endpoint, ![]() is exactly the
round-trip time of the connection, and
is exactly the
round-trip time of the connection, and ![]() is zero.
is zero.
The OSTT-based estimation of the RTT is independent of the location of the monitoring
point.
For example, the arrival of segments at the second monitoring point in Figure 4.3
provides a sample
![]() which is equal to
which is equal to ![]() .
This is a substantial improvement over existing methods, since it implies that we can
perform RTT estimation for connections observed at any point on their path.
Previous work, such as Aikat et al. [AKSJ03], constrained itself to traces
collected very close the edge of the path, so they could assume that the delay
between the monitoring point and local networks was minimal. This results in
an estimate in which only
.
This is a substantial improvement over existing methods, since it implies that we can
perform RTT estimation for connections observed at any point on their path.
Previous work, such as Aikat et al. [AKSJ03], constrained itself to traces
collected very close the edge of the path, so they could assume that the delay
between the monitoring point and local networks was minimal. This results in
an estimate in which only ![]() is computed under the assumption that
is computed under the assumption that ![]() is very small.
The use of the sum of the OSTTs is more flexible, since it makes it possible to
extract RTTs from any trace, and not just edge traces. This allowed us to analyze
a backbone trace like Abilene-I, making our traffic analysis and generation technique
more widely applicable.
is very small.
The use of the sum of the OSTTs is more flexible, since it makes it possible to
extract RTTs from any trace, and not just edge traces. This allowed us to analyze
a backbone trace like Abilene-I, making our traffic analysis and generation technique
more widely applicable.
There are, however, a number of difficulties with OSTT-based round-trip time estimation.
A first problem is that each pair of segments provides a different estimation
of the OSTT (due to differences in queuing delay and other sources of
delay variability), so we have to decide how to combine the OSTT
samples from one side of the connection with those from the other side.
In other words, each connection provides a set of OSTT samples for
one side,
![]() , and another set of OSTT
samples for the other side,
, and another set of OSTT
samples for the other side,
![]() , where
, where
![]() and
and ![]() are not necessarily equal. The question is then how to
combine these samples into a single estimate of
are not necessarily equal. The question is then how to
combine these samples into a single estimate of ![]() , which we will call
, which we will call
![]() . If we assume
low variability, we could simply sum the means of the two sets of estimates,
. If we assume
low variability, we could simply sum the means of the two sets of estimates,
A second problem is that the sum of OSTT samples requires at least one sequence number/acknowledgment number pair for each side of the connection. Otherwise, one of the sets of OSTT samples is empty, and we have no information about the delay on one side of the connection. This prevents us from using the sum of OSTTs estimator for connections that send data only in one direction.
Finally, we must note that the time between the arrival of a data segment and its first acknowledgment is not always a good estimator of the OSTT. This is mostly due to two causes: retransmission ambiguity and delayed acknowledgments. Retransmissions may create ambiguous cases in which we cannot match the pair of data and ACK segments. This is the well-known retransmission ambiguity problem, which was first discussed by Karn and Partridge [KP88b] in the context of estimation of TCP's retransmission timeout. Whenever a data segment is retransmitted, it is not possible to decide whether to compute the OSTT using the first or the second instance of the data segment. These data segments cannot therefore be used to obtain a new OSTT sample. This retransmission ambiguity is similar to the SYN retransmission problem shown in Figure 4.2.
Delayed acknowledgments can add up to 500 milliseconds4.4 [Bra89] of extra delay in the OSTT estimates, whenever a segment is not acknowledged immediately. Figure 4.4 illustrates this problem. The right side OSTT is 200 milliseconds larger than it should be due to the delayed sending of the acknowledgment in segment 2. The distortion of OSTT samples caused by delayed acknowledgments is pervasive, since the number of segments in a window is often an odd number, and TCP implementations are allowed to keep (at most) one unacknowledged segment. An odd number of segments in a window means that the last segment does not trigger an immediate acknowledgment, which adds an extra delay to its corresponding sample. Furthermore, performance enhancement heuristics implemented in modern TCP stacks often add PUSH flags to TCP segments carrying data in the middle of an ADU, and this flag forces the other endpoint to immediately send an acknowledgment [Pos81]. This creates even more cases in which the last segment of the window has to be acknowledged separately using a delayed acknowledgment. The empirical results presented below illustrate the impact of this problem.
![\includegraphics[width=3in]{fig/netw-level-tests/netw-level-test-1.eps}](img197.png)
|
![\includegraphics[width=3in]{fig/netw-level-tests/netw-level-test-1-nodelacks.eps}](img198.png)
|
We evaluated the round-trip time estimation techniques proposed above
using synthetic traffic in a testbed where RTTs could be controlled precisely.
Figure 4.5 shows the results of a first experiment,
in which a uniform distribution of round-trip times between 10 and 500
milliseconds was simulated using a modified version of dummynet [Riz97].
Each connection had exactly the same round-trip time throughout its
lifetime, so every one of its segments was artificially delayed by the same
amount.
During the
experiment, a large number of single epoch connections was created.
The sizes of ![]() and
and ![]() for each connection were
randomly sampled from a uniform distribution with values between 10,000
and 50,000 bytes. We collected a segment header trace of the traffic and
applied the round-trip time estimation techniques described above.
Figures 4.5 and 4.6
compare the results.
As shown in Figure 4.5 the SYN estimator can measure the distribution of round-trip times
flawlessly in this experiment. The input distribution of RTTs (marked with white squares)
exactly matches the distribution computed using the SYN estimator
(marked with white triangles).
for each connection were
randomly sampled from a uniform distribution with values between 10,000
and 50,000 bytes. We collected a segment header trace of the traffic and
applied the round-trip time estimation techniques described above.
Figures 4.5 and 4.6
compare the results.
As shown in Figure 4.5 the SYN estimator can measure the distribution of round-trip times
flawlessly in this experiment. The input distribution of RTTs (marked with white squares)
exactly matches the distribution computed using the SYN estimator
(marked with white triangles).
Figure 4.5 also studies the accuracy of several OSTT-based estimators. As discussed in the previous
section, the analysis of the OSTTs in a TCP connection results in two sets of estimations,
![]() and
and
![]() ,
for the initiator-to-monitor side and for the acceptor-to-monitor side respectively.
For each connection, the estimated round-trip time
,
for the initiator-to-monitor side and for the acceptor-to-monitor side respectively.
For each connection, the estimated round-trip time ![]() has to be derived from these
collections of numbers.
The figure shows the result of computing the distribution of round-trip
times using four different methods of deriving
has to be derived from these
collections of numbers.
The figure shows the result of computing the distribution of round-trip
times using four different methods of deriving ![]() .
The first method is the sum-of-minima, where
.
The first method is the sum-of-minima, where ![]() is the
sum of the minimum value in
is the
sum of the minimum value in
![]() and the minimum
value in
and the minimum
value in
![]() . In the figure, the sum-of-minima
estimation of the distribution of round-trip times (marked with white circles)
is exactly on top of the input distribution, so this estimator is exact.
The same is also true when the sum of medians is used. This shows that there is
no significant variability between the minimum and the median of each set
of OSTTs, which is expected in our uncongested experimental environment.
. In the figure, the sum-of-minima
estimation of the distribution of round-trip times (marked with white circles)
is exactly on top of the input distribution, so this estimator is exact.
The same is also true when the sum of medians is used. This shows that there is
no significant variability between the minimum and the median of each set
of OSTTs, which is expected in our uncongested experimental environment.
Figure 4.5 shows another two distributions derived from
OSTT samples that are less accurate characterizations of the real RTT distribution
in the testbed experiment.
The distribution (marked with black triangles) of round-trip times obtained
using the sum of the mean of the OSTTs, i.e., Equation 4.1,
is slightly heavier that the real distribution of round-trip times.
This is due to the presence of a few OSTT samples that are above the real OSTT of the
connection, which skew the mean but not the median or the minimum.
The magnitude of these larger samples is strikingly illustrated by the curve
corresponding to the sum of the maximum OSTTs (marked with back circles).
This curve is far heavier than the previous one, and certainly a poor representative
of the original distribution of round-trip times. The use of the maximum makes
this last estimator focus on the largest OSTTs, which are shown to be quite far from
the true values of the OSTT.
The exact cause of this inaccuracy is the use of delayed acknowledgments in TCP,
which was illustrated in Figure 4.4. Delayed acknowledgments make some OSTT
samples include extra delays due to the behavior of the TCP stack and not the
path between the endpoints. In particular, the distribution computed using
the sum-of-maxima is 200 milliseconds heavier than the input distribution for most of its
values. This is consistent with the default value of FreeBSD's delayed acknowledgment
mechanism, which is 100 milliseconds. Connections where both the initiator-to-monitor and the![]() acceptor-to-monitor sets of OSTTs have values from delayed acknowledgments result
in values of
acceptor-to-monitor sets of OSTTs have values from delayed acknowledgments result
in values of ![]() equal to
equal to ![]() milliseconds.
milliseconds.
To confirm this hypothesis, we conducted a second experiment, with exactly the same setup, although this time TCP's delayed acknowledgment mechanism was completely disabled. The results of estimating the distribution of round-trip times in this second experiment are shown in Figure 4.6. Every estimation method is accurate in this case, which proves our hypothesis about the impact of delayed acknowledgments. The conclusion is that the first three estimators are preferable, since they are robust to the inaccuracy that delayed acknowledgments introduce when measuring round-trip times from segment header traces. Interestingly, the impact of delayed acknowledgment on passive RTT estimation has been overlooked in the literature [Ost,AKSJ03,JD02].
![\includegraphics[width=3in]{fig/netw-level-tests/netw-level-test-2.eps}](img200.png)
|
![\includegraphics[width=3in]{fig/netw-level-tests/netw-level-test-3.eps}](img201.png)
|
The discussion of the RTT estimation methods in the previous section pointed out the need to filter out samples from retransmissions. The previous two experiments were run in an uncongested testbed, where no losses were expected. Since loss is common in the real traces that we study in this dissertation, we further validated these methods using experiments where dummynet was used to introduce artificial loss rates under our control. Figure 4.7 compares the six distributions obtained using the six RTT estimators in an experiment with a fixed loss rate of 1%. Once again the first three estimators measure the distribution of physical round-trip times accurately, while the sum-of-means and the sum-of-maxima overestimate the true distribution. The overestimation is even more pronounced in another experiment in which loss rates were uniformly distributed between 0% and 10%. The estimated RTT distributions are shown in Figures 4.8 and 4.10. The first figure uses the same range in the x-axis as Figure 4.7, while the second figure uses a broader range in the x-axis, between 0 and 5 seconds. The first three estimators are not affected by losses, but the RTT distribution computed by the sum-of-means estimator is substantially heavier than the original. Similarly, the distribution computed by the sum-of-maxima is several times larger than the real distribution.
![\includegraphics[width=3in]{fig/seg-diagram/ostt-loss.eps}](img202.png)
|
The cause of the additional inaccuracy in the sum-of-means estimator is the
interaction between losses and TCP's cumulative acknowledgment mechanism, which
prevent us from disambiguating samples from retransmissions.
This problem is illustrated in Figure 4.9.
Segments 1 and 2 with sequence numbers ![]() and
and ![]() respectively are
sent from the initiator to the acceptor, but segment 1 is lost before
the monitor. Since TCP's acknowledgments are cumulative,
this means that the acceptor endpoint cannot acknowledge
segment 2 alone4.5.
Some time later, after the
initiator times out, another segment with sequence number
respectively are
sent from the initiator to the acceptor, but segment 1 is lost before
the monitor. Since TCP's acknowledgments are cumulative,
this means that the acceptor endpoint cannot acknowledge
segment 2 alone4.5.
Some time later, after the
initiator times out, another segment with sequence number ![]() is sent
from initiator to acceptor. Upon its arrival, the acceptor can send a cumulative
acknowledgment with sequence number
is sent
from initiator to acceptor. Upon its arrival, the acceptor can send a cumulative
acknowledgment with sequence number ![]() . Using the timestamps of segments
2 and 4, we could compute an OSTT
. Using the timestamps of segments
2 and 4, we could compute an OSTT ![]() . However,
. However, ![]() is clearly not
a good representative of the OSTT between the monitor and the acceptor, and
therefore this sample is incorrect. The true value of the OSTT would be
the difference between the timestamps of segments 3 and 4, which is much
smaller than
is clearly not
a good representative of the OSTT between the monitor and the acceptor, and
therefore this sample is incorrect. The true value of the OSTT would be
the difference between the timestamps of segments 3 and 4, which is much
smaller than ![]() .
In this example, filtering samples from retransmitted
sequence numbers does not help, since no retransmission was observed
for
.
In this example, filtering samples from retransmitted
sequence numbers does not help, since no retransmission was observed
for ![]() . In general, it is important to either filter out any sample
associated with reordering (e.g., segment 3 which has a lower sequence number than
segment 2), or use an estimator, such as the sum-of-medians, that is robust
to the distortion created by samples like
. In general, it is important to either filter out any sample
associated with reordering (e.g., segment 3 which has a lower sequence number than
segment 2), or use an estimator, such as the sum-of-medians, that is robust
to the distortion created by samples like ![]() .
Otherwise, OSTTs can be substantially overestimated, as illustrated in
Figure 4.8.
.
Otherwise, OSTTs can be substantially overestimated, as illustrated in
Figure 4.8.
![\includegraphics[width=3in]{fig/netw-level-tests/netw-level-test-3.xmax_5.eps}](img206.png)
|
![\includegraphics[width=3in]{fig/netw-level-tests/netw-level-test-5.eps}](img207.png)
|
Figure 4.11 reports on another experiment in which round-trip times were distributed between 10 and 4,000 milliseconds, and the underlying loss rate was 1%. Unlike the previous experiments, the SYN estimator results in a lighter distribution of round-trip times than the original one. This is due to the SYN retransmission timeout, which is set to 3 seconds [Bra89]. Connections with a round-trip time above 3 seconds always retransmit their SYN segment, and therefore make their SYN estimator invalid. Therefore, these connections provide no samples when the SYN estimator is used, resulting in a distribution of RTTs limited to a maximum of 3 seconds. However, in these cases, the sum-of-minima and the sum-of-medians estimator were again able to estimate the distribution of round-trip times accurately.
![\includegraphics[width=3in]{fig/netw-level-params/abi-leip-unc.rtt_new.cdf.eps}](img208.png)
|
![\includegraphics[width=3in]{fig/netw-level-params/abi-leip-unc.rtt_bytes.cdf.eps}](img209.png)
|
Figure 4.12 shows the distributions of round-trip times computed using the sum-of-minima estimator for the five traces listed in Table 3.1. The first observation is that the distribution of round-trip times is significantly variable across sites and for different times of the day at the same site. While the majority of round-trip times are between 7 milliseconds and 1 second for UNC and Leipzig, they are distributed in a far narrower range, between 20 milliseconds and 400 milliseconds, for Abilene-I. This is probably due to the fact that the Abilene-I trace was collected in the middle of a backbone network that mostly carries traffic between US universities and research centers so intercontinental round-trip times are very uncommon in this trace. This is also a lightly loaded network, so extra delays due to queuing are very uncommon. Note also that the distributions for UNC become lighter as we consider busier times of the day. The cause for this is an open question. The distribution for Leipzig-II does not exactly match any of the ones for UNC, but its body fluctuates within the envelope formed by the UNC distributions.
Figure 4.13 shows the same distributions but the probability of each round-trip time is computed for each byte rather than for each connection. A probability of 0.5 in this plot means that 50% of the bytes were carried in connections with a round-trip time of a given value or less. For example, for the UNC 1 AM trace, 50% of the bytes were carried in connections that experienced round-trip times of 110 milliseconds or less. Previously (e.g., Figure 4.12) a probability of 0.5 meant that 50% of the connections experienced round-trip times of a given value or less. In general, we observe that the smallest round-trip times are somewhat less significant in terms of bytes than they are in terms of connections. Interestingly, Abilene-I does not differ much from the other distributions in this case. Another interesting observation is that a substantial number of bytes in the Leipzig-II traces were carried in connections with round-trip times between 300 milliseconds and 3 seconds, and this phenomenon is not observed for the other distributions. This could be explained by the location of this link in Europe, and the fact that it may carry a significant amount of traffic to distant US servers.
![\includegraphics[width=3in]{fig/netw-level-params/unc04-aug3-1pm.rtt.cdf.eps}](img210.png)
|
![\includegraphics[width=3in]{fig/netw-level-params/leip.rtt.cdf.eps}](img211.png)
|
Figures 4.14 and 4.15 compare the variability
in the results when different estimators are used for the same trace. In the UNC 1 PM trace
and the Leipzig-II trace, the
sum-of-medians estimator results in a somewhat heavier distribution of round-trip
times but maintains more or less the same shape of the distribution.
Given that these estimators were shown to
be robust to losses and TCP artifacts in the previous section, the difference between
the sum-of-minima and the sum-of-medians seems due to true round-trip time variability.
While we are not implementing RTT variability within individual TCP connections in our experiments,
it seems possible to reproduce
this variability during traffic generation. This could be achieved by combining
the distributions from the sum-of-minima and the sum-of-medians to give connections
more variable round-trip times. For example, given a connection with a sum-of-minima
estimate of ![]() and sum-of-medians estimate of
and sum-of-medians estimate of
![]() , let
, let
![]() . During traffic generation,
the segments of this connection could be delayed by a random quantity between
. During traffic generation,
the segments of this connection could be delayed by a random quantity between
![]() and
and
![]() , or some variation
of this scheme. Note that this basic method needs to be refined to eliminate
segment reordering, which would occur frequently with the described approach.
, or some variation
of this scheme. Note that this basic method needs to be refined to eliminate
segment reordering, which would occur frequently with the described approach.
When a segment is received by a TCP endpoint, its payload is stored in an operating system buffer until the application uses a system call to receive the data. In order to avoid overflowing this buffer, TCP endpoints use a field in the TCP header to tell each other about the amount of free space in this buffer, and they never send more data than can possibly fit in this buffer. This mechanism, known as flow control, imposes a limit on the maximum throughput of a TCP connection. A sender can never send more data than the amount of free buffer space at the receiver. We refer to this free space as the receiver window size. The TCP header of each segment includes the size of the receiver window on the sender endpoint at the time the segment was sent. This value is often called the ``advertised'' window size, and defined as a ``receiver-side limit on the amount of outstanding (i.e., unacknowledged) data'' by RFC 2581 [APS99]. The size of the advertised window shrinks as new data reach the endpoint (since data are placed in the TCP buffer), and grows when the application using the TCP connection consumes these data (which are removed from the TCP buffer).
A TCP connection with a maximum receiver window of ![]() segments4.6,
a maximum segment size of
segments4.6,
a maximum segment size of ![]() bytes,
and a round-trip time of
bytes,
and a round-trip time of ![]() seconds, can at most send data at
seconds, can at most send data at
![]() bytes per second. This peak throughput
can be further constrained by the capacity of the path
bytes per second. This peak throughput
can be further constrained by the capacity of the path ![]() , so peak throughput
is
, so peak throughput
is
![]() . As we will show, connections often use small
receiver window sizes that significantly constrain performance,
i.e.,
. As we will show, connections often use small
receiver window sizes that significantly constrain performance,
i.e.,
![]() ,
and this should be taken into account during traffic generation.
,
and this should be taken into account during traffic generation.
We can measure the distribution of receiver window sizes by examining segment headers. As pointed out in [CHC$^+$04b], some TCP implementations (e.g., Microsoft Windows) do not report their maximum receiver window size in their first segment (i.e., the SYN or SYN-ACK) as one would expect, but do it in their first data segment. This is because some implementations allocate a small amount of buffering (e.g., 4 KB) to new TCP connections, but increase this amount after connection establishment is successfully completed (e.g., increasing it to 32 KB). In our work, we compute the maximum receiver window sizes as the maximum value of the advertised window size observed in the segments of each TCP connection. This gives us two maximum receiver window sizes per connection, one for each endpoint. There is no reason why the two endpoints must use receiver windows of equal size.
![\includegraphics[width=3in]{fig/netw-level-params/abi-leip-unc.win.cdf.eps}](img218.png)
|
![\includegraphics[width=3in]{fig/netw-level-params/abi-leip-unc.win_bytes.cdf.eps}](img219.png)
|
Figure 4.16 shows the distribution of maximum receiver window sizes
in five traces. In general, window sizes are a multiple of the maximum segment size
(usually 1,460 bytes), so we observe numerous jumps in the cumulative distribution
function. Notice for example the jumps at 12 segments,
![]() bytes (approximately 16 KB), and 44 segments,
bytes (approximately 16 KB), and 44 segments,
![]() bytes
(approximately 64 KB). The field in the TCP header that specifies
the receiver window size is 16 bits long, so the maximum receiver window size is
65,535 bytes4.7.
bytes
(approximately 64 KB). The field in the TCP header that specifies
the receiver window size is 16 bits long, so the maximum receiver window size is
65,535 bytes4.7.
We can make two interesting observations from Figure 4.16. First, a significant fraction of the connections used small receiver window sizes in all traces. For example, between 45% and 65% of the connections had window sizes below 20,000 bytes. Second, we observe a surprising difference between the UNC distributions and those from Leipzig-II and Abilene-I. We see a much larger fraction of the largest windows at UNC, suggesting a different distribution of endpoint TCP implementations, or widespread tuning of the servers located on the UNC campus. This is in sharp contrast to the results for round-trip times, where Leipzig-II and UNC were alike and quite different from Abilene-I.
Figure 4.17 shows an alternative view of the distributions of maximum receiver window sizes by computing the probability that each byte in the traces was carried in a connection with certain maximum receiver window size. The plot shows that connections with the largest window sizes carry many more bytes than those with small sizes. This is likely to be explained by tuning of the TCP endpoint parameters by administrators and server vendors in environments with large data transfers.
TCP reacts to loss by retransmitting segments, which makes TCP a reliable transport
protocol, and reducing its sending rate, a mechanism known as congestion control.
The reduction in sending rate is implemented using a TCP variable known as the congestion window size ![]() ,
which further limits the maximum number of packets that can be sent by one endpoint.
Throughout the lifetime of a TCP connection, TCP endpoints are only allowed to have a maximum of
,
which further limits the maximum number of packets that can be sent by one endpoint.
Throughout the lifetime of a TCP connection, TCP endpoints are only allowed to have a maximum of ![]() outstanding (unacknowledged) segments in the network. This limits peak throughput to
outstanding (unacknowledged) segments in the network. This limits peak throughput to
![]() .
.
The size of the congestion window is reduced every time TCP detects loss, so lossy connections
have lower throughput than lossless ones.
Numerous papers have developed analytical
expressions that consider the impact of loss on average throughput.
These papers make use of different analysis techniques and consider different models
of TCP behavior and loss patterns. However, the simple relationship between loss and rate
given in [MSM97] is enough to illustrate the basic impact of loss.
In general, the average throughput of a TCP connection is
![]() , where
, where
![]() is the maximum segment size,
is the maximum segment size, ![]() is a constant equal to
is a constant equal to
![]() ,
,
![]() is the round-trip time and
is the round-trip time and
![]() is the loss rate. Therefore, average throughput is inversely proportional to the square
root of the loss rate
is the loss rate. Therefore, average throughput is inversely proportional to the square
root of the loss rate ![]() , and it decreases very quickly as
, and it decreases very quickly as ![]() increases. Note that the
maximum window size is not part of this equation, but peak throughput is still limited by
increases. Note that the
maximum window size is not part of this equation, but peak throughput is still limited by
![]() (and by round-trip time), as mentioned above.
(and by round-trip time), as mentioned above.
We define the loss rate of a TCP connection as the number of lost segments divided by the total
number of segments sent, ![]() . Assuming segments have an equal probability of loss, the loss rate
is equal to the probability of losing an individual segment.
Measuring the exact loss rate experienced by a TCP connection depends on our ability to count
all segments, including those that may be lost before the monitoring
point, and detecting all losses, which may occur before or after the monitoring point.
The exact calculation of the loss rate of a connection is a very difficult task.
In our work, we make use of two heuristics that should provide a good approximation of a
connection's loss rate. We make no attempt to address the most difficult
and ambiguous cases of loss detection, which our experience leads us to believe are uncommon.
. Assuming segments have an equal probability of loss, the loss rate
is equal to the probability of losing an individual segment.
Measuring the exact loss rate experienced by a TCP connection depends on our ability to count
all segments, including those that may be lost before the monitoring
point, and detecting all losses, which may occur before or after the monitoring point.
The exact calculation of the loss rate of a connection is a very difficult task.
In our work, we make use of two heuristics that should provide a good approximation of a
connection's loss rate. We make no attempt to address the most difficult
and ambiguous cases of loss detection, which our experience leads us to believe are uncommon.
Our measurement of loss rate from traces of segment headers relies on detecting
retransmissions and making use of the same indications of loss that TCP employs.
For each connection, we compute the total number of segments transmitted ![]() as the total number
of data segments in the connection.
In addition, we compute the total number of lost segments
as the total number
of data segments in the connection.
In addition, we compute the total number of lost segments
![]() using the number of retransmitted data segments
using the number of retransmitted data segments ![]() , and the number
of triple duplicate acknowledgment events
, and the number
of triple duplicate acknowledgment events ![]() .
We need both numbers
.
We need both numbers ![]() and
and ![]() , since they provide complementary information.
Triple duplicates can tell us about losses that occur before the monitoring point,
which do not create observable retransmissions.
Retransmissions can tell us about losses recovered using the retransmission timer,
which do not create triple duplicates.
, since they provide complementary information.
Triple duplicates can tell us about losses that occur before the monitoring point,
which do not create observable retransmissions.
Retransmissions can tell us about losses recovered using the retransmission timer,
which do not create triple duplicates.
Estimating the loss rate ![]() of a TCP connection simply as
of a TCP connection simply as ![]() tends to overestimate
loss rate when the monitoring point is located after the point of loss.
In the most common situation, when the loss of a segment in one direction happens before the monitoring point,
the trace collected at the monitoring point includes no retransmission and sends
three duplicate acknowledgments in the opposite direction.
These acknowledgments share the same sequence number, which corresponds to the sequence number
of the segment that preceded (according to TCP's logical data order) the lost segment.
However, when the loss happens after the monitoring point, the trace includes both
a retransmission, in the direction in which the loss occurred, and a triple duplicate
acknowledgment event, in the opposite direction.
We can therefore compute a better estimate of loss rate by ignoring the triple duplicate
events whenever a corresponding retransmission is observed. Doing so means that triple duplicates are
used to estimate loss before the monitoring point, while retransmissions are used to
estimate loss after the monitoring point.
Applying this idea, the estimate of loss rate that we use in our work is therefore
tends to overestimate
loss rate when the monitoring point is located after the point of loss.
In the most common situation, when the loss of a segment in one direction happens before the monitoring point,
the trace collected at the monitoring point includes no retransmission and sends
three duplicate acknowledgments in the opposite direction.
These acknowledgments share the same sequence number, which corresponds to the sequence number
of the segment that preceded (according to TCP's logical data order) the lost segment.
However, when the loss happens after the monitoring point, the trace includes both
a retransmission, in the direction in which the loss occurred, and a triple duplicate
acknowledgment event, in the opposite direction.
We can therefore compute a better estimate of loss rate by ignoring the triple duplicate
events whenever a corresponding retransmission is observed. Doing so means that triple duplicates are
used to estimate loss before the monitoring point, while retransmissions are used to
estimate loss after the monitoring point.
Applying this idea, the estimate of loss rate that we use in our work is therefore
![]() , where
, where ![]() includes only triple duplicate events not associated
with observed retransmissions.
includes only triple duplicate events not associated
with observed retransmissions.
Note also that our computation of the loss rate considers only losses of data segments, and not
losses of pure acknowledgments. Losses of acknowledgments can also reduce the size of the congestion window ![]() ,
but measuring acknowledgment loss rate is even harder given the
cumulative nature of the acknowledgment numbers and the fact that endpoints may acknowledge
every data segment received, or every other data segment. We are not overly concerned by this simplification.
This is because under the assumption
that losses are caused by congestion, pure acknowledgments are far less likely to be
dropped given their much smaller size.
,
but measuring acknowledgment loss rate is even harder given the
cumulative nature of the acknowledgment numbers and the fact that endpoints may acknowledge
every data segment received, or every other data segment. We are not overly concerned by this simplification.
This is because under the assumption
that losses are caused by congestion, pure acknowledgments are far less likely to be
dropped given their much smaller size.
![\includegraphics[width=3in]{fig/netw-level-tests/netw-level-test-6-8.eps}](img235.png)
|
In order to study the accuracy of our estimation of loss rates, we conduct a number of
controlled experiments similar to those used to evaluate the different round-trip
time estimation techniques.
Figure 4.18 shows the results of two laboratory experiments in which
an artificial loss rate of 1% was imposed on connections carrying a single epoch
with
![]() bytes. Transferring ADUs of this size requires a minimum
of 6,850 data segments.
Losses were created using dummynet , so each
connection in the experiment had a drop probability equal to 0.01.
The figure illustrates several points about our loss rate computation.
We first compare the measured loss rates for two scenarios: one where a segment loss
probability of 0.01 was applied by dummynet only to one direction of the connections,
and another one where it was applied to both directions. In Figure 4.18,
the first scenario is labeled ``unidirectional loss experiment'' and the second is labeled
``bidirectional loss experiment''.
The mean value of the data segment loss rate in the unidirectional loss experiment (marked with white triangles)
was 1%, exactly the intended value.
We also observe that 90% of the connections experienced loss rates between 0.5% and 1.5%.
The bidirectional loss experiment (results marked with white squares)
illustrates the dependency between the two directions of a TCP
connection. The mean of the CDF is substantially higher for this experiment, and the distribution
shows a fixed positive offset of 20%. This is because losses of acknowledgments in one direction
also triggered retransmissions in the other, increasing the measured (data segment) loss rate. In other
words, loss of acknowledgments inflated the estimated loss rates, since data was not really lost.
bytes. Transferring ADUs of this size requires a minimum
of 6,850 data segments.
Losses were created using dummynet , so each
connection in the experiment had a drop probability equal to 0.01.
The figure illustrates several points about our loss rate computation.
We first compare the measured loss rates for two scenarios: one where a segment loss
probability of 0.01 was applied by dummynet only to one direction of the connections,
and another one where it was applied to both directions. In Figure 4.18,
the first scenario is labeled ``unidirectional loss experiment'' and the second is labeled
``bidirectional loss experiment''.
The mean value of the data segment loss rate in the unidirectional loss experiment (marked with white triangles)
was 1%, exactly the intended value.
We also observe that 90% of the connections experienced loss rates between 0.5% and 1.5%.
The bidirectional loss experiment (results marked with white squares)
illustrates the dependency between the two directions of a TCP
connection. The mean of the CDF is substantially higher for this experiment, and the distribution
shows a fixed positive offset of 20%. This is because losses of acknowledgments in one direction
also triggered retransmissions in the other, increasing the measured (data segment) loss rate. In other
words, loss of acknowledgments inflated the estimated loss rates, since data was not really lost.
Our second observation about Figure 4.18 is that the range of the two distributions is quite wide, showing substantial variability around the target loss rate of 1%. This is partly explained by the random sampling in dummynet 's implementation of per-flow loss rates. Dummynet drops segments in an independent manner, by generating a random number between 0 and 1 for each segment, and only dropping a segment if its corresponding random number is between 0 and 0.01. This means that even with large ADUs, the drop probability rate experienced by the connection in the testbed experiments was not exactly 0.01.
In order to study the impact of this random sampling, we conduct a numerical simulation, and the result is illustrated using the third CDF in Figure 4.18. This distribution comes from simulating each connection by sampling a uniform distribution (with a range between 0 and 1) 6,850 times (the number of data segments in 10 MB). Each sample is meant to simulate one segment that may or may not be lost. If the value of the sample is equal to or greater than 0.01, the segment is not counted as a loss. If the sampled value is less than 0.01, the segment is counted as a loss. In this case, we continue to sample the uniform distribution until the value obtained is equal to or greater than 0.01. These extra samples are used to simulate the possibility of losing retransmissions, which can also be dropped by dummynet with the same probability. The result of this sampling process is two counts:
The CDF from the numerical simulation provides us with a gold standard for our measurements, since our loss rate estimates should reflect the actual drop rates that dummynet imposed to the connections in the testbed. Still, further work is need to explain the remaining difference, and possibly refine our measurement technique. In any case, the experiments serve to confirm that our loss rate estimate is reasonably close to the true loss.
![\includegraphics[width=3in]{fig/netw-level-params/abi-leip-unc.loss.cdf.eps}](img241.png)
|
![\includegraphics[width=3in]{fig/netw-level-params/abi-leip-unc.loss_bytes.cdf.eps}](img242.png)
|
The distributions of loss rates in our collection of real traces is shown in Figure 4.19. Between 92.5% and 96.2% of the connections did not experience any losses, while the remaining connections did experience quite significant loss rates. This is consistent across all measured sites. The result is quite different when the probability is computed in terms of bytes rather than in terms of connections, as shown in Figure 4.20. Most bytes were carried in connections that experience at least some loss. We can also observe that Abilene-I's connections were substantially less affected by loss than the connections in the other traces, since Abilene-I's CDF shows higher cumulative probabilities. For example, the distribution for the Abilene-I trace shows that only 8% of the bytes were carried in connections with 1% loss or more. The distributions for the rest of the traces show that between 20% and 34% of the bytes were carried in connections with 1% loss or more. Loss is specially significant at UNC, where 34% of the bytes were carried by connections with loss rates above 1% (a high loss rate). Interestingly, the UNC trace with the highest load (UNC 1 PM) had a lighter distribution of per-byte loss rates.
Doctoral Dissertation: Generation and Validation of Empirically-Derived TCP Application Workloads
© 2006 Félix Hernández-Campos
![\includegraphics[scale=0.4]{fig/seg-diagram/syn-rtt.eps}](img182.png)
![\includegraphics[width=3in]{fig/seg-diagram/syn-rtt-loss.eps}](img183.png)
![\includegraphics[width=3in]{fig/seg-diagram/syn-rtt-retr.eps}](img184.png)
![\includegraphics[width=3in]{fig/seg-diagram/ostt.eps}](img185.png)
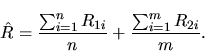
![\includegraphics[width=3in]{fig/seg-diagram/ostt2.eps}](img196.png)