
Research Assistant Professor
Department of Computer Science
University of North Carolina at Chapel Hill
Tel: (919) 962 1703
Fax: (919) 962 1699
E-mail: jmf@cs.unc.edu
| |
Jan-Michael Frahm Research Assistant Professor Department of Computer Science University of North Carolina at Chapel Hill Tel: (919) 962 1703 Fax: (919) 962 1699 E-mail: jmf@cs.unc.edu |
| Home |
Research |
Publications |
Curriculum |
Tutorials |
Markerless Augmented Reality | ||
| The subject of augmented
reality is to insert virtual objects into real scenes. We developed a system for high quality markerless augmented reality
with realistic direct illumination of the virtual objects. The
lights of the scene are localized and are used for direct
illumination of the virtual object placed in the scene. Our method
keeps the augmented scene unaffected to overcome the limitations of
many systems, which require markers or additional
equipment in the scene to reconstruct illumination. |
||
Short description of the markerless augmented reality system |
Realistic illumination of virtual objects placed in real scenes and
observed by a moving camera is one of the important challenges of an
augmented reality system. It is in particular difficult, if the scene
has to remain unaffected like for augmented TV productions. There it is
often not possible to place additional equipment within the scene,
because the augmentation pops up only for a short time. Before and
after that time slot it is unacceptable to have any additional devices
like markers or mirror spheres in view.
The proposed approach computes a realistic illumination by observing
the whole scene and its surrounding environment with a two camera
system consisting of a TV-camera and a fish-eye camera. The TV-camera
is used for camera pose estimation and the fish-eye camera is employed
to localize the light sources. In the field of augmented reality it is required to have reliable tracks of the camera poses during the recording. Our system achieves this without placing markers in the field of view of the camera in contrast to most of the current systems do. We use a two camera system as shown in figure 1. It consists of a TV-camera, which captures the images used for the augmentation, and a fish-eye camera capturing the scene and the surrounding environment (whole studio).  figure 1: image of the used two camera system Applying structure from motion algorithms from computer vision to the images of both cameras allows computation of the camera pose without any markers in the scene. It identifies 3D interest points and computes their positions (see figure 2). From these 3D interest points the camera position is estimated and afterwards the camera calibration is determined. 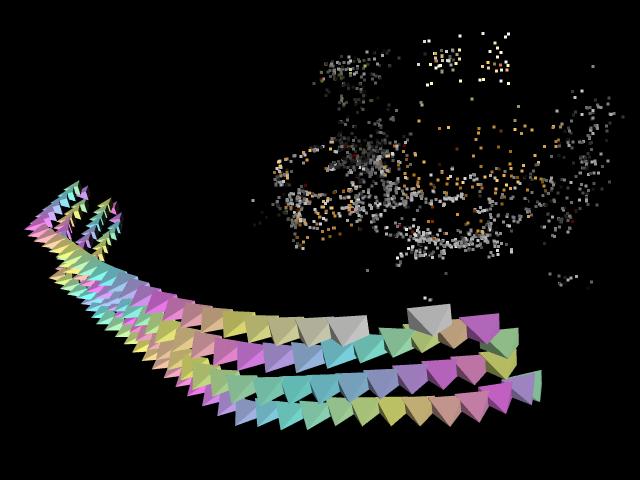 figure 2: cameras and 3D interest point cloud We run a reconstruction on some image sequences captured by the TV-camera and the fish-eye camera before the show. It delivers 3D interest scene points for both cameras. These two independent reconstructions are afterwards aligned automatically to each other. The aligned cameras are shown in figure 3.  figure 3: aligned TV-cameras and fisheye-cameras One of the major limitations of the structure from motion algorithms is, that the reconstructed 3D point positions and also the camera poses are scaled, rotated and translated against the real world, which makes it difficult to place virtual objects into the scene beforehand. Our proposed system overcomes this limitation by capturing the scene beforehand, which establishes a coordinate system for the scene which can be recovered by employing the same 3D interest scene points later. It can be seen as a ``learning'' of the scene structure and it is employed to place virtual objects in the scene. For the shadow computation of the virtual objects, segmented scene planes are used by our technique. A shadow map is created by rendering the scene with the segmented scene plane. This shadow map is used afterwards as an alpha texture for the scene plane during the augmentation. The fish-eye camera is exploited to detect the light sources of the scene. The estimated light sources are transferred from the fish-eye coordinate system into the coordinate frame of the TV-camera by applying the transformation between both reconstructions. This enables a direct illumination for the virtual object placed in the coordinate system of TV-camera. |