
I lead the computer vision group at Dawnlight, founded and advised by Fei-Fei Li, working on the next generation of ambient intelligence using machine learning. We build video based human activity and object recognition systems for real-time processing on edge computers. Previously I was a researcher at eBay, where I developed deep learning models for large scale product recognition and visual search.
I am passionate about fundamental and applied research, building and growing diverse teams to bridge the gap between academia and industry and delivering scalable AI solutions that reach the public.
I did my PhD in Computer Science at University of North Carolina at Chapel Hill, where I was advised by
Tamara Berg and worked closely with Alex Berg and Svetala Lazebnik. My thesis was on large scale visual recognition clothing, people and fashion styles.
I am interested in all aspects of computer vision and related learning problems. Some of my current and past projects include efficient deep learning for edge computing, action recognition, pose estimation, generative models, multimodal vision, semantic segmentation, object detection, image-text embeddings, large scale visual search and fine-grained classification.
Muyang Li,
M. Hadi Kiapour,
Ji Lin,
Song Han
Under review, 2021
We present a flexible spatio-temporal attention module for recognizing Activities of Daily Living (ADL). Our approach fuses RGB or Depth with pose streams. It allows each joint to attend to its \emph{own} salient region across time and space simultaneously. This allows our method to capture subtle human object interactions required for fine-grained recognition. Also, our approach extends to low-lighting setting, a significantly less explored variation, when RGB is no longer useful. We take advantage of depth stream and incorporate context using a single scene frame. Experiments show that our method outperforms the previous state-of-the-art results of action recognition on two prominent ADL datasets: ETRI-Activity3D (+4.2\% accuracy) and Toyota Smarthome (+10.1\% class accuracy) in the day setting. In the night setting, our method also outperforms the previous state-of-the-art results on Toyota Smarthome (+6.3\% class accuracy) without using the RGB video stream.
@inproceedings{LiArXiv21day,
Author = {Muyang Li, M. Hadi Kiapour, Ji Lin and Song Han},
Title = {Day-night Consistent Attention for Daily Living Action Recognition},
Journal = {Under Review},
Year = {2021}
}

Shuai Zheng,
Fan Yang,
M. Hadi Kiapour,
Robinson Piramuthu
ACM Multimedia Conference (ACM MM), 2018 (~Oral)
Understanding clothing from a single image has strong commercial and cultural impacts on modern societies. However, this task remains a challenging computer vision problem due to wide variations in the appearance, style, brand and layering of clothing items. We present a new database called ModaNet, a large-scale collection of images based on Paperdoll dataset. Our dataset provides 55,176 street images, fully annotated with polygons on top of the 1 million weakly annotated street images in Paperdoll. ModaNet aims to provide a technical benchmark to fairly evaluate the progress of applying the latest computer vision techniques that rely on large data for fashion understanding. The rich annotation of the dataset allows to measure the performance of state-of-the-art algorithms for object detection, semantic segmentation and polygon prediction on street fashion images in detail.
@inproceedings{zhengACMMM18modanet,
Author = {Shuai Zheng, Fan Yang, M. Hadi Kiapour and Robinson Piramuthu},
Title = {ModaNet: A Large-Scale Street Fashion Dataset with Polygon Annotations},
Journal = {ACM Multimedia Conference (ACM MM)},
Year = {2018}
}

M. Hadi Kiapour,
Robinson Piramuthu
European Conference on Computer Vision (ECCV), 2018
First Workshop on Computer Vision For Fashion, Art and Design
While lots of people may think branding begins and ends with a logo, fashion brands communicate their uniqueness through a wide range of visual cues such as color, patterns and shapes. In this work, we analyze learned visual representations by deep networks that are trained to recognize fashion brands. In particular, the activation strength and extent of neurons are studied to provide interesting insights about visual brand expressions. The proposed method identifies where a brand stands in the spectrum of branding strategy, i.e., from trademark-emblazoned goods with bold logos to implicit no logo marketing. By quantifying attention maps, we are able to interpret the visual characteristics of a brand present in a single image and model the general design direction of a brand as a whole. We further investigate versatility of neurons and discover ``specialists" that are highly brand-specific and ``generalists" that detect diverse visual features. A human experiment based on three main visual scenarios of fashion brands is conducted to verify the alignment of our quantitative measures with the human perception of brands. This paper demonstrate how deep networks go beyond logos in order to recognize clothing brands in an image.
@inproceedings{kiapourECCV18every,
Author = {Kiapour, Hadi and
Piramuthu, Robinson},
Title = {Every Brand is a Story: Going beyond Logos in Fashion Brands by Visual Understanding},
Journal = {First Workshop on Computer Vision For Fashion, Art and Design, European Conference on Computer Vision (ECCV)},
Year = {2018}
}

Bryan A. Plummer,
Paige Kordas,
M. Hadi Kiapour,
Shuai Zheng,
Robinson Piramuthu,
Svetlana Lazebnik
European Conference on Computer Vision (ECCV), 2018
This paper presents an approach for grounding phrases in images which jointly learns multiple text-conditioned embeddings in a single end-to-end model. In order to differentiate text phrases into semantically distinct subspaces, we propose a concept weight branch that automatically assigns phrases to embeddings, whereas prior works predefine such assignments. Our proposed solution simplifies the representation requirements for individual embeddings and allows the underrepresented concepts to take advantage of the shared representations before feeding them into concept-specific layers. Comprehensive experiments verify the effectiveness of our approach across three phrase grounding datasets, Flickr30K Entities, ReferIt Game and Visual Genome, where we obtain a (resp.) 3.5%, 2%, and 3.5% improvement in grounding performance over a strong region-phrase embedding baseline.
@inproceedings{plummerECCV18conditional,
Author = {Bryan A. Plummer and Paige Kordas and
M. Hadi Kiapour and Shuai Zheng and Robinson Piramuthu
and Svetlana Lazebnik},
Title = {Conditional Image-Text Embedding Networks},
Journal = {European Conference on Computer Vision (ECCV)},
Year = {2018}
}
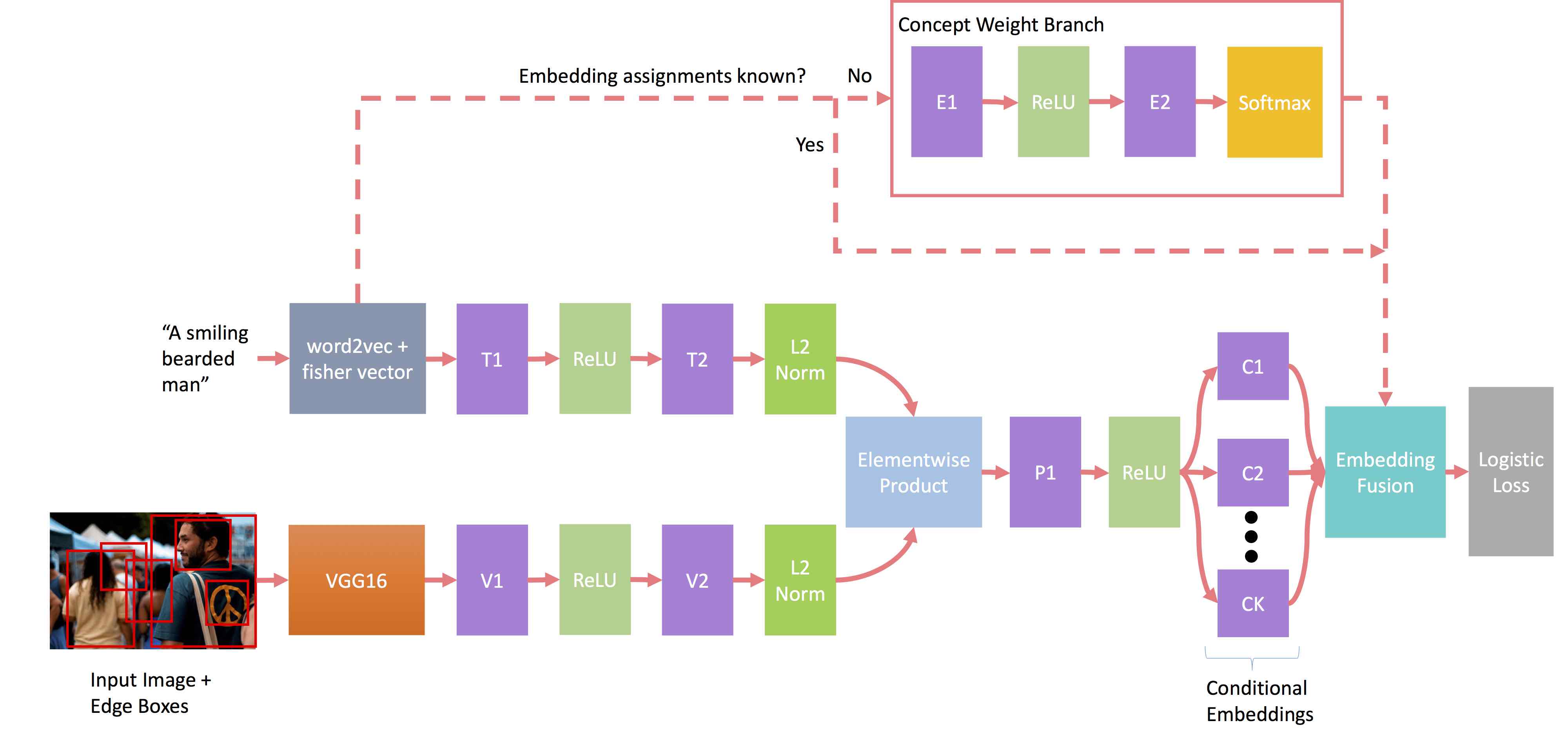
Bryan A. Plummer,
M. Hadi Kiapour,
Shuai Zheng,
Robinson Piramuthu
arXiv, 2018
In this paper, we introduce an attribute-based interactive image search with human-in-the-loop feedback to iteratively refine the image search results. We study active image search where human feedback is solicited exclusively in visual form, without using relative attribute annotations used in prior work, which are expensive to collect for large datasets. In order to optimize the image selection strategy, a deep reinforcement model is trained to take advantage of the interplay between attributes. Additionally, we extend the recently introduced Conditional Similarity Network to incorporate global similarity in training visual embeddings, which results in a more natural transition as the user explores the learned similarity embeddings. Our experiments demonstrate the effectiveness of our approach by producing compelling results on both active image search and image attribute representation tasks.
@inproceedings{plummerarXiv18give,
Author = {Bryan A. Plummer and M. Hadi Kiapour and
Shuai Zheng and Robinson Piramuthu},
Title = {Give me a hint! Navigating Image Databases using Human-in-the-loop Feedback},
Journal = {arXiv},
Year = {2018}
}
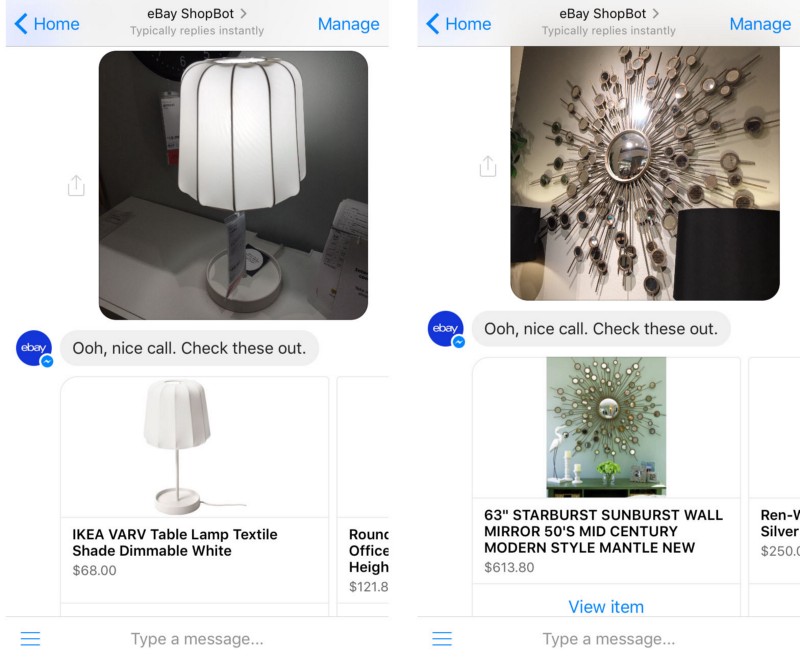
Fan Yang,
Ajinkya Kale,
Yury Bubnov,
Leon Stein,
Qiaosong Wang,
M. Hadi Kiapour,
Robinson Piramuthu
ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 2017
In this paper, we propose a novel end-to-end approach for scalable visual search infrastructure. We discuss the challenges we faced for a massive volatile inventory like at eBay and present our solution to overcome those. We harness the availability of large image collection of eBay listings and state-of-the-art deep learning techniques to perform visual search at scale. Supervised approach for optimized search limited to top predicted categories and also for compact binary signature are key to scale up without compromising accuracy and precision. Both use a common deep neural network requiring only a single forward inference. The system architecture is presented with in-depth discussions of its basic components and optimizations for a trade-off between search relevance and latency. This solution is currently deployed in a distributed cloud infrastructure and fuels visual search in eBay ShopBot and Close5. We show benchmark on ImageNet dataset on which our approach is faster and more accurate than several unsupervised baselines. We share our learnings with the hope that visual search becomes a first class citizen for all large scale search engines rather than an afterthought.
@inproceedings{yangKDD17visual,
Author = {Fan Yang and Ajinkya Kale and
Yury Bubnov and Leon Stein and Qiaosong Wang and
Hadi Kiapour and Robinson Piramuthu},
Title = {Visual Search at eBay},
Journal = {ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), Applied Data Science Track},
Year = {2017}
}
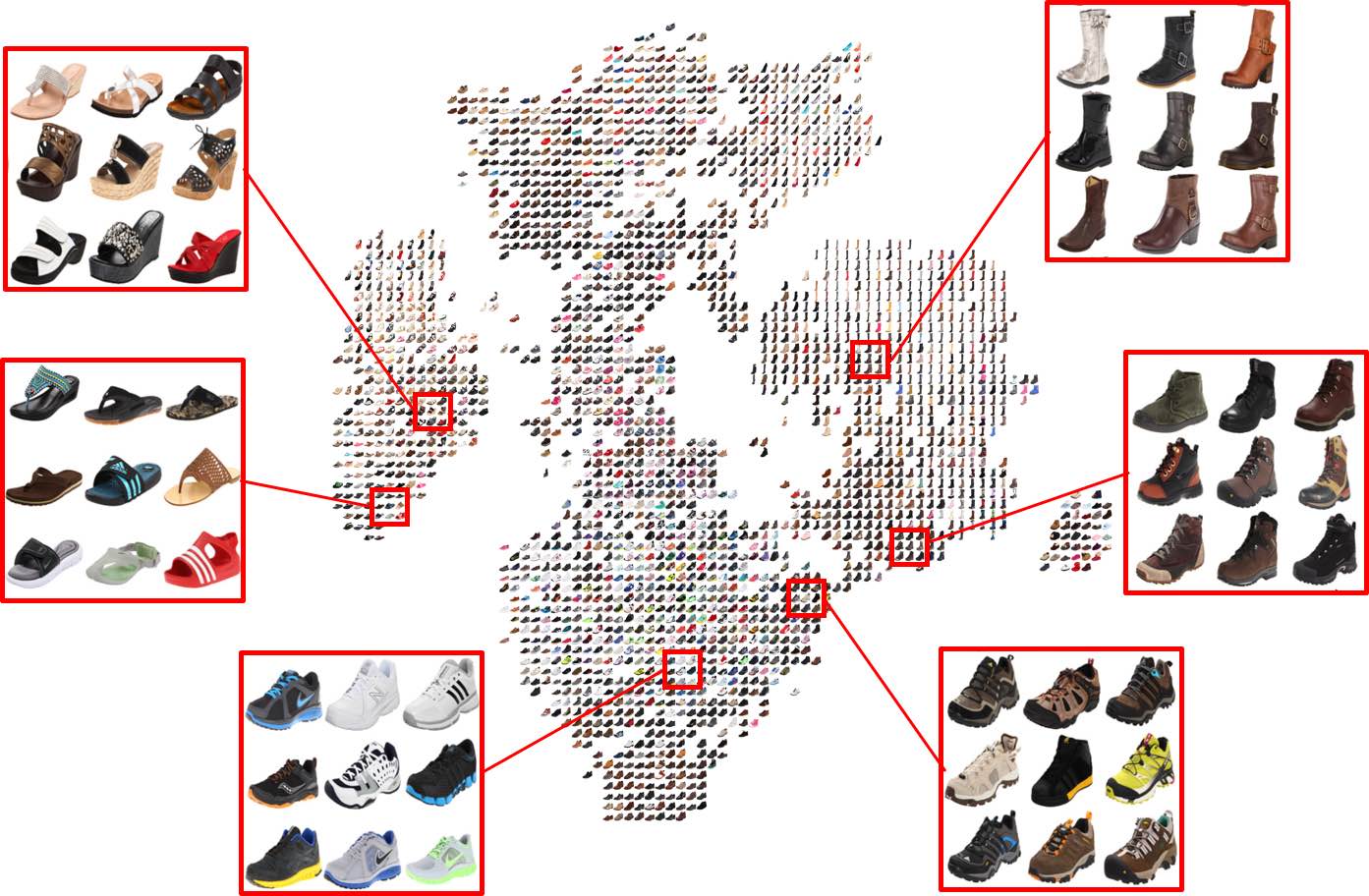
M. Hadi Kiapour,
Xufeng Han,
Svetlana Lazebnik,
Alexander C. Berg,
Tamara L. Berg
International Conference on Computer Vision (ICCV), 2015 (~Oral presentation)
In this paper, we define a new task, Exact Street to Shop, where our goal is to match a real-world example of a garment item to the same item in an online shop. This is an extremely challenging task due to visual differences between street photos (pictures of people wearing clothing in everyday uncontrolled settings) and online shop photos (pictures of clothing items on people, mannequins, or in isolation, captured by professionals in more controlled settings). We collect a new dataset for this application containing 404,683 shop photos collected from 25 different online retailers and 20,357 street photos, providing a total of 39,479 clothing item matches between street and shop photos. We develop three different methods for Exact Street to Shop retrieval, including two deep learning baseline methods, and a method to learn a similarity measure between the street and shop domains. Experiments demonstrate that our learned similarity significantly outperforms our baselines that use existing deep learning based representations.
@inproceedings{kiapourICCV15where,
Author = {M. Hadi Kiapour and Xufeng Han and
Svetlana Lazebnik and Alexander C. Berg and Tamara L. Berg},
Title = {Where to Buy It: Matching Street Clothing Photos to Online Shops},
Journal = {International Conference on Computer Vision (ICCV)},
Year = {2015}
}

M. Hadi Kiapour,
Wei Di,
Vignesh Jagadeesh,
Robinson Piramuthu
International Conference on Image Processing (ICIP), 2015
While discriminative visual element mining has been introduced before, in this paper we present an approach that requires minimal annotation in both training and test time. Given only a bounding box that contains the foreground objects, it automatically transforms the input images into a roughly-aligned pose space and automatically discovers the most discriminative visual fragments of each category. These fragments are then used to learn robust classifiers that discriminate between very similar categories under challenging conditions such as large variations in pose or habitats. The minimal required input, is a critical characteristic that enables our approach to easily generalize over other visual domains. Moreover, our approach takes advantage of deep networks that are targeted towards fine-grained classification. It learns mid-level representations that are specific to a category and generalize well across the category instances at the same time. Our evaluations show that the automatically learned representation based on discriminative fragments, significantly outperforms globally extracted deep features in classification accuracy.
@inproceedings{kiapourICIP15mine,
Author = {M. Hadi Kiapour and Wei Di and
Vignesh Jagadeesh and Robinson Piramuthu},
Title = {Mine the Fine: Fine-Grained Fragment Discovery},
Journal = {International Conference on Image Processing (ICIP)},
Year = {2015}
}

M. Hadi Kiapour,
Kota Yamaguchi,
Alexander C. Berg,
Tamara L. Berg
European Conference on Computer Vision (ECCV), 2014
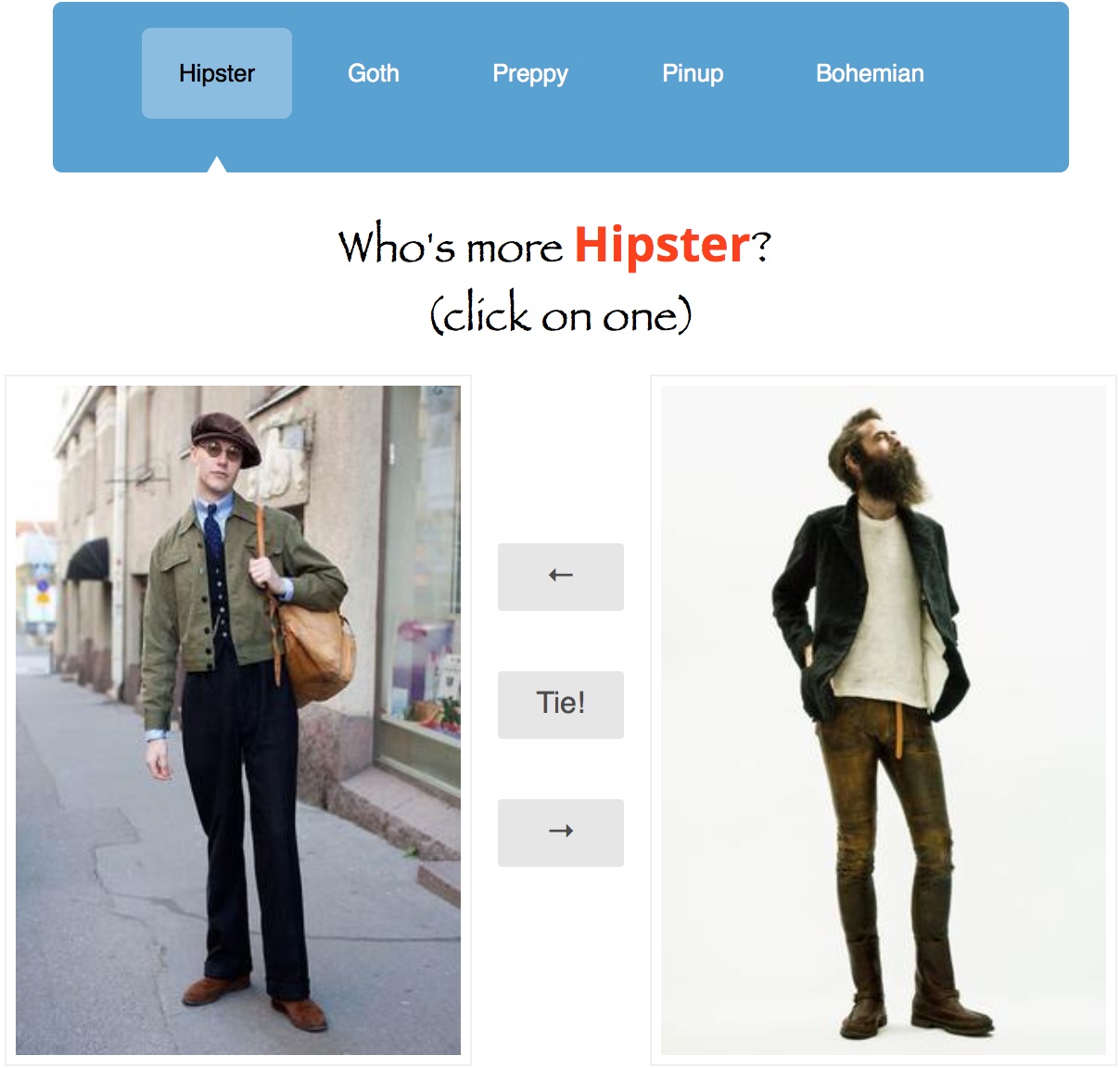
The clothing we wear and our identities are closely tied, revealing to the world clues about our wealth, occupation, and socioidentity. In this paper we examine questions related to what our clothing reveals about our personal style. We first design an online competitive Style Rating Game called Hipster Wars to crowd source reliable human judgments of style. We use this game to collect a new dataset of clothing outfits with associated style ratings for 5 style categories: hipster, bohemian, pinup, preppy, and goth. Next, we train models for between class and within-class classification of styles. Finally, we explore methods to identify clothing elements that are generally discriminative for a style, and methods for identifying items in a particular outfit that may indicate a style.
@inproceedings{kiapourECCV14hipster,
Author = {M. Hadi Kiapour and Kota Yamaguchi and
Alexander C. Berg and Tamara L. Berg},
Title = {Hipster Wars: Discovering Elements of Fashion Styles},
Journal = {European Conference on Computer Vision (ECCV)},
Year = {2014}
}
M. Hadi Kiapour,
Kevin Yager,
Alexander C. Berg,
Tamara L. Berg
IEEE Winter Conference on Applications of Computer Vision (WACV), 2014
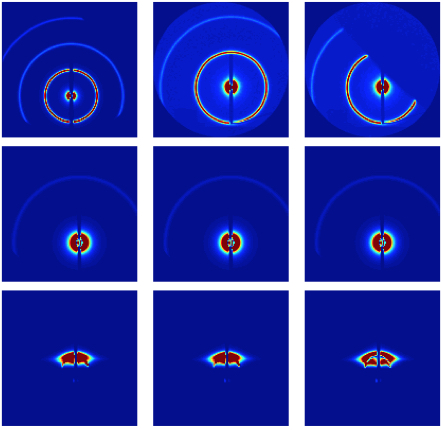
We explore the use of computer vision methods for organizing, searching, and classifying x-ray scattering images. X-ray scattering is a technique that shines an intense beam of x-rays through a sample of interest. By recording the intensity of x-ray deflection as a function of angle, scientists can measure the structure of materials at the molecular and nano-scale. Current and planned synchrotron instruments are producing x-ray scattering data at an unprecedented rate, making the design of automatic analysis techniques crucial for future research. In this paper, we devise an attribute-based approach to recognition in x-ray scattering images and demonstrate applications to image annotation and retrieval.
@inproceedings{kiapourWACV14materials,
Author = {M. Hadi Kiapour and Kevin Yager and
Alexander C. Berg and Tamara L. Berg},
Title = {Materials Discovery: Fine-Grained Classification of X-ray Scattering Images},
Journal = {IEEE Winter Conference on Applications of Computer Vision (WACV)},
Year = {2014}
}
Kota Yamaguchi,
M. Hadi Kiapour,
Luis E. Ortiz,
Tamara L. Berg
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2014
Clothing recognition is a societally and commercially important yet extremely challenging problem due to large variations in clothing appearance, layering, style, and body shape and pose. In this paper, we tackle the clothing parsing problem using a retrieval-based approach. For a query image, we find similar styles from a large database of tagged fashion images and use these examples to recognize clothing items in the query. Our approach combines parsing from: pre-trained global clothing models, local clothing models learned on the fly from retrieved examples, and transferred parse-masks (Paper Doll item transfer) from retrieved examples. We evaluate our approach extensively and show significant improvements over previous state-of-the-art for both localization (clothing parsing given weak supervision in the form of tags) and detection (general clothing parsing). Our experimental results also indicate that the general pose estimation problem can benefit from clothing parsing.
@inproceedings{yamaguchiTPAMI14retrieving,
Author = {Kota Yamaguchi and M. Hadi Kiapour and
Luis E. Ortiz and Tamara L. Berg},
Title = {Retrieving Similar Styles to Parse Clothing},
Journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
Year = {2014}
}

Kota Yamaguchi,
M. Hadi Kiapour,
Tamara L. Berg
International Conference on Computer Vision (ICCV), 2013
Clothing recognition is an extremely challenging problem due to wide variation in clothing item appearance, layering, and style. In this paper, we tackle the clothing parsing problem using a retrieval based approach. For a query image, we find similar styles from a large database of tagged fashion images and use these examples to parse the query. Our approach combines parsing from: pre-trained global clothing models, local clothing models learned on the fly from retrieved examples, and transferred parse masks (paper doll item transfer) from retrieved examples. Experimental evaluation shows that our approach significantly outperforms state of the art in parsing accuracy.
@inproceedings{yamaguchiICCV13paper,
Author = {Kota Yamaguchi and M. Hadi Kiapour and
Tamara L. Berg},
Title = {Paper Doll Parsing: Retrieving Similar Styles to Parse Clothing Items},
Journal = {International Conference on Computer Vision (ICCV)},
Year = {2013}
}

Kota Yamaguchi,
M. Hadi Kiapour,
Luis E. Ortiz,
Tamara L. Berg
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2012
In this paper we demonstrate an effective method for parsing clothing in fashion photographs, an extremely challenging problem due to the large number of possible garment items, variations in configuration, garment appearance, layering, and occlusion. In addition, we provide a large novel dataset and tools for labeling garment items, to enable future research on clothing estimation. Finally, we present intriguing initial results on using clothing estimates to improve pose identification, and demonstrate a prototype application for pose-independent visual garment retrieval.
@inproceedings{yamaguchiICVPR12parsing,
Author = {Kota Yamaguchi and M. Hadi Kiapour and
Luis E. Ortiz and Tamara L. Berg},
Title = {Parsing Clothing in Fashion Photographs},
Journal = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
Year = {2012}
}

M. Khademi,
M. Hadi Kiapour,
M. T. Manzuri,
A. Kiaei,
International Workshop on Artificial Neural Networks in Pattern Recognition (ANNPR), 2010
In this paper an accurate real-time sequence-based system for representation, recognition, interpretation, and analysis of the facial action units (AUs) and expressions is presented. Our system has the following characteristics: 1) employing adaptive-network-based fuzzy inference systems (ANFIS) and temporal information, we developed a classification scheme based on neuro-fuzzy modeling of the AU intensity, which is robust to intensity variations, 2) using both geometric and appearance-based features, and applying efficient dimension reduction techniques, our system is robust to illumination changes and it can represent the subtle changes as well as temporal information involved in formation of the facial expressions, and 3) by continuous values of intensity and employing top-down hierarchical rule-based classifiers, we can develop accurate human-interpretable AU-to-expression converters. Extensive experiments on Cohn-Kanade database show the superiority of the proposed method, in comparison with support vector machines, hidden Markov models, and neural network classifiers.
@inproceedings{khademiANNPR10analysis,
Author = {M. Khademi and M. Hadi Kiapour and
M. T. Manzuri, A. Kiaei},
Title = {Analysis, Interpretation, and Recognition of Facial Action Units and Expressions Using Neuro-Fuzzy Modeling },
Journal = {International Workshop on Artificial Neural Networks in Pattern Recognition},
Year = {2010}
}

M. Khademi,
M. T. Manzuri,
M. Hadi Kiapour,
A. Kiaei,
International Workshop on Multiple Classifier Systems (MCS), 2010
Facial Action Coding System consists of 44 action units (AUs) and more than 7000 combinations. Hidden Markov models (HMMs) classifier has been used successfully to recognize facial action units (AUs) and expressions due to its ability to deal with AU dynamics. However, a separate HMM is necessary for each single AU and each AU combination. Since combinations of AU numbering in thousands, a more efficient method will be needed. In this paper an accurate real-time sequence-based system for representation and recognition of facial AUs is presented. Our system has the following characteristics: 1) employing a mixture of HMMs and neural network, we develop a novel accurate classifier, which can deal with AU dynamics, recognize subtle changes, and it is also robust to intensity variations, 2) although we use an HMM for each single AU only, by employing a neural network we can recognize each single and combination AU, and 3) using both geometric and appearance-based features, and applying efficient dimension reduction techniques, our system is robust to illumination changes and it can represent the temporal information involved in formation of the facial expressions. Extensive experiments on Cohn-Kanade database show the superiority of the proposed method, in comparison with other classifiers.
@inproceedings{khademiMCS10recognizing,
Author = {M. Khademi and M. T. Manzuri and
M. Hadi Kiapour and A. Kiaei},
Title = {Recognizing Combinations of Facial Action Units with
Different Intensity Using a Mixture of Hidden Markov Models and Neural Network},
Journal = {International Workshop on Multiple Classifier Systems},
Year = {2010}
}
